多模态 API
“所有自然连接的事物都应该结合起来教授”——约翰·阿莫斯·夸美纽斯,《感官世界图》,1658
人类同时通过多种数据输入模式处理知识。我们学习的方式,我们的经验都是多模态的。我们不仅仅拥有视觉、听觉和文本。
与这些原则相反,机器学习通常专注于针对单一模态处理的专用模型。例如,我们开发了用于文本转语音或语音转文本等任务的音频模型,以及用于对象检测和分类等任务的计算机视觉模型。
然而,新一波多模态大型语言模型开始涌现。例如 OpenAI 的 GPT-4o、Google 的 Vertex AI Gemini 1.5、Anthropic 的 Claude3,以及开源产品 Llama3.2、LLaVA 和 BakLLaVA,它们能够接受多种输入,包括文本、图像、音频和视频,并通过整合这些输入生成文本响应。
| 多模态大型语言模型(LLM)功能使模型能够结合其他模态(如图像、音频或视频)处理和生成文本。 |
Spring AI 多模态
多模态指的是模型同时理解和处理来自各种来源信息的能力,包括文本、图像、音频和其他数据格式。
Spring AI 消息 API 提供了支持多模态 LLM 所需的所有抽象。
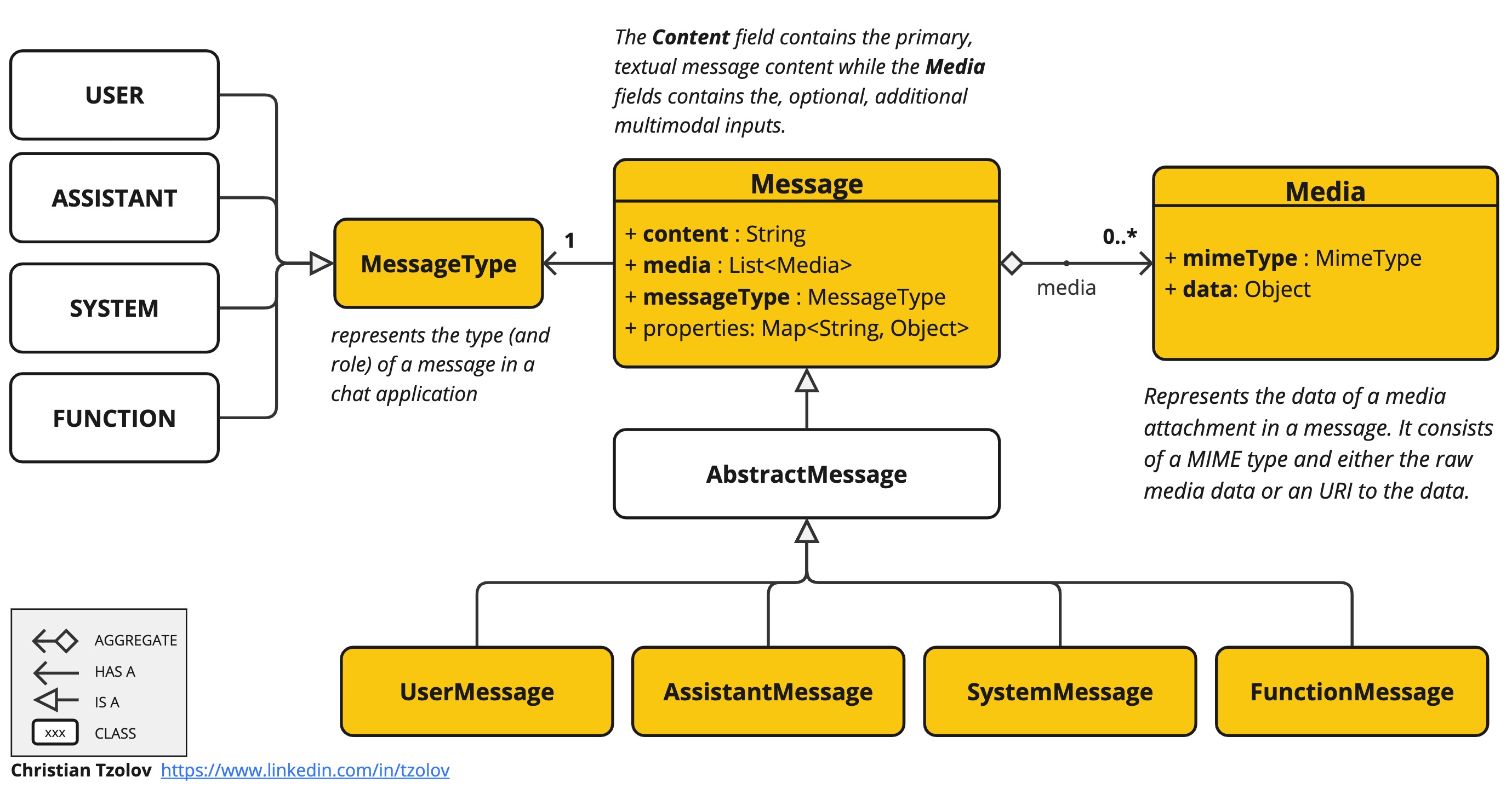
UserMessage 的 content 字段主要用于文本输入,而可选的 media 字段允许添加一个或多个不同模态的附加内容,例如图像、音频和视频。MimeType 指定模态类型。根据所使用的 LLM,Media 数据字段可以是作为 Resource 对象的原始媒体内容,也可以是内容的 URI。
目前,媒体字段仅适用于用户输入消息(例如,UserMessage)。它对系统消息不重要。包含 LLM 响应的 AssistantMessage 仅提供文本内容。要生成非文本媒体输出,您应该使用专用的、单一模态模型。* |
例如,我们可以将以下图片(multimodal.test.png)作为输入,并要求 LLM 解释它所看到的内容。

对于大多数多模态 LLM,Spring AI 代码将类似于这样
var imageResource = new ClassPathResource("/multimodal.test.png");
var userMessage = UserMessage.builder()
.text("Explain what do you see in this picture?") // content
.media(new Media(MimeTypeUtils.IMAGE_PNG, this.imageResource)) // media
.build();
ChatResponse response = chatModel.call(new Prompt(this.userMessage));或者使用流畅的 ChatClient API
String response = ChatClient.create(chatModel).prompt()
.user(u -> u.text("Explain what do you see on this picture?")
.media(MimeTypeUtils.IMAGE_PNG, new ClassPathResource("/multimodal.test.png")))
.call()
.content();并产生类似这样的响应
这是一张带有简单设计的果盘图片。果盘由金属制成,边缘是弯曲的铁丝,形成了一个开放的结构,使得水果可以从各个角度看到。果盘内,有两根黄色香蕉放在一个似乎是红苹果的上面。香蕉略微过熟,这可以通过它们皮上的棕色斑点看出。果盘顶部有一个金属环,可能用作提手。果盘放在一个中性背景的平面上,可以清晰地看到里面的水果。
Spring AI 为以下聊天模型提供多模态支持

