控制 Step 流程
通过将步骤分组到一个拥有 Job 中,需要能够控制 Job 如何从一个步骤“流转”到另一个步骤。Step 的失败不一定意味着 Job 应该失败。此外,可能有不止一种“成功”类型来决定接下来应该执行哪个 Step。取决于如何配置一组 Steps,某些步骤甚至可能完全不会被处理。
|
流程定义中的 Step Bean 方法代理
步骤实例在流程定义中必须是唯一的。当一个步骤在流程定义中有多个结果时,重要的是将同一个步骤实例传递给流程定义方法(如 在以下示例中,步骤作为参数注入到流程或 Job 的 bean 定义方法中。这种依赖注入方式保证了步骤在流程定义中的唯一性。然而,如果流程是通过调用使用 有关 Spring Framework 中 bean 方法代理的更多详细信息,请参阅使用 @Configuration 注解部分。 |
顺序流程
最简单的流程场景是 Job 中的所有步骤按顺序执行,如下图所示
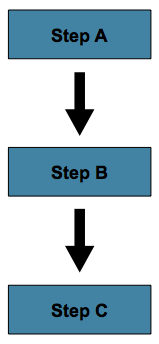
这可以通过在 step 中使用 next 来实现。
-
Java
-
XML
以下示例展示了如何在 Java 中使用 next() 方法
@Bean
public Job job(JobRepository jobRepository, Step stepA, Step stepB, Step stepC) {
return new JobBuilder("job", jobRepository)
.start(stepA)
.next(stepB)
.next(stepC)
.build();
}以下示例展示了如何在 XML 中使用 next 属性
<job id="job">
<step id="stepA" parent="s1" next="stepB" />
<step id="stepB" parent="s2" next="stepC"/>
<step id="stepC" parent="s3" />
</job>在上述场景中,stepA 首先运行,因为它是列出的第一个 Step。如果 stepA 正常完成,则 stepB 运行,依此类推。然而,如果 step A 失败,整个 Job 失败,并且 stepB 不会执行。
使用 Spring Batch XML 命名空间时,配置中列出的第一个步骤总是由 Job 运行的第一个步骤。其他步骤元素的顺序无关紧要,但第一个步骤必须始终出现在 XML 的最前面。 |
条件流程
在前面的示例中,只有两种可能性
-
step成功,并且应该执行下一个step。 -
step失败,因此job应该失败。
在许多情况下,这可能足够了。然而,如果一个 step 的失败应该触发另一个不同的 step,而不是导致失败,该怎么办?下图展示了这样一个流程
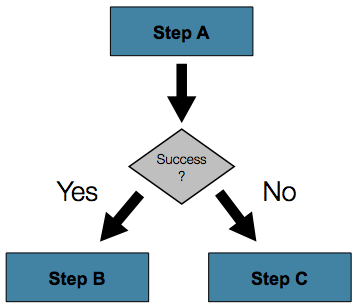
-
Java
-
XML
Java API 提供了一组流式方法,允许你指定流程以及在步骤失败时应采取的操作。以下示例展示了如何指定一个步骤 (stepA),然后根据 stepA 是否成功,继续执行两个不同步骤 (stepB 或 stepC) 中的一个
@Bean
public Job job(JobRepository jobRepository, Step stepA, Step stepB, Step stepC) {
return new JobBuilder("job", jobRepository)
.start(stepA)
.on("*").to(stepB)
.from(stepA).on("FAILED").to(stepC)
.end()
.build();
}为了处理更复杂的场景,Spring Batch XML 命名空间允许你在 step 元素中定义 transition 元素。其中一种转换是 next 元素。与 next 属性一样,next 元素告诉 Job 下一步要执行哪个 Step。然而,与属性不同的是,一个给定的 Step 可以有任意数量的 next 元素,并且在失败情况下没有默认行为。这意味着,如果使用了 transition 元素,则必须显式定义 Step 转换的所有行为。另请注意,单个步骤不能同时具有 next 属性和 transition 元素。
next 元素指定了一个匹配模式和下一步要执行的步骤,如下例所示
<job id="job">
<step id="stepA" parent="s1">
<next on="*" to="stepB" />
<next on="FAILED" to="stepC" />
</step>
<step id="stepB" parent="s2" next="stepC" />
<step id="stepC" parent="s3" />
</job>-
Java
-
XML
使用 Java 配置时,on() 方法使用简单的模式匹配方案来匹配 Step 执行产生的 ExitStatus。
使用 XML 配置时,transition 元素的 on 属性使用简单的模式匹配方案来匹配 Step 执行产生的 ExitStatus。
模式中只允许使用两个特殊字符
-
*匹配零个或多个字符 -
?精确匹配一个字符
例如,c*t 匹配 cat 和 count,而 c?t 匹配 cat 但不匹配 count。
虽然 Step 上的 transition 元素数量没有限制,但如果 Step 执行产生的 ExitStatus 未被任何元素覆盖,框架会抛出异常并导致 Job 失败。框架会自动将 transition 元素按从最具体到最不具体的顺序排列。这意味着,即使在前面示例中 stepA 的顺序颠倒了,FAILED 的 ExitStatus 仍然会流转到 stepC。
BatchStatus 与 ExitStatus 的区别
为条件流程配置 Job 时,理解 BatchStatus 和 ExitStatus 之间的区别非常重要。BatchStatus 是 JobExecution 和 StepExecution 的一个属性,是一个枚举类型,框架使用它来记录 Job 或 Step 的状态。它可以是以下值之一:COMPLETED(完成),STARTING(启动中),STARTED(已启动),STOPPING(停止中),STOPPED(已停止),FAILED(失败),ABANDONED(已放弃),或 UNKNOWN(未知)。其中大多数都是自解释的:COMPLETED 是步骤或 Job 成功完成时设置的状态,FAILED 是失败时设置的状态,依此类推。
-
Java
-
XML
以下示例展示了使用 Java 配置时的 on 元素
...
.from(stepA).on("FAILED").to(stepB)
...以下示例展示了使用 XML 配置时的 next 元素
<next on="FAILED" to="stepB" />乍一看,似乎 on 引用了其所属 Step 的 BatchStatus。然而,它实际上引用的是 Step 的 ExitStatus。顾名思义,ExitStatus 表示 Step 完成执行后的状态。
-
Java
-
XML
使用 Java 配置时,前面 Java 配置示例中所示的 on() 方法引用了 ExitStatus 的退出码。
更具体地说,使用 XML 配置时,前面 XML 配置示例中所示的 next 元素引用了 ExitStatus 的退出码。
用白话来说,它表示:“如果退出码是 FAILED,则转到 stepB”。默认情况下,步骤的退出码总是与其 BatchStatus 相同,这就是前面的配置起作用的原因。但是,如果退出码需要不同怎么办?一个很好的例子来自 samples 项目中的 skip 示例 Job
-
Java
-
XML
以下示例展示了如何在 Java 中处理不同的退出码
@Bean
public Job job(JobRepository jobRepository, Step step1, Step step2, Step errorPrint1) {
return new JobBuilder("job", jobRepository)
.start(step1).on("FAILED").end()
.from(step1).on("COMPLETED WITH SKIPS").to(errorPrint1)
.from(step1).on("*").to(step2)
.end()
.build();
}以下示例展示了如何在 XML 中处理不同的退出码
<step id="step1" parent="s1">
<end on="FAILED" />
<next on="COMPLETED WITH SKIPS" to="errorPrint1" />
<next on="*" to="step2" />
</step>step1 有三种可能性
-
Step失败,在这种情况下 Job 应该失败。 -
Step成功完成。 -
Step成功完成,但退出码为COMPLETED WITH SKIPS。在这种情况下,应运行不同的步骤来处理错误。
前面的配置有效。然而,需要根据执行跳过记录的情况来改变退出码,如下例所示
public class SkipCheckingListener implements StepExecutionListener {
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
String exitCode = stepExecution.getExitStatus().getExitCode();
if (!exitCode.equals(ExitStatus.FAILED.getExitCode()) &&
stepExecution.getSkipCount() > 0) {
return new ExitStatus("COMPLETED WITH SKIPS");
} else {
return null;
}
}
}前面的代码是一个 StepExecutionListener,它首先检查以确保 Step 成功,然后检查 StepExecution 上的跳过计数是否大于 0。如果两个条件都满足,则返回一个带有退出码 COMPLETED WITH SKIPS 的新 ExitStatus。
配置停止行为
在讨论了BatchStatus 和 ExitStatus 之后,可能会想知道 Job 的 BatchStatus 和 ExitStatus 是如何确定的。虽然步骤的状态是由执行的代码决定的,但 Job 的状态是根据配置确定的。
到目前为止,所有讨论的 Job 配置都至少有一个没有转换的最终 Step。
-
Java
-
XML
在以下 Java 示例中,step 执行后,Job 结束
@Bean
public Job job(JobRepository jobRepository, Step step1) {
return new JobBuilder("job", jobRepository)
.start(step1)
.build();
}在以下 XML 示例中,step 执行后,Job 结束
<step id="step1" parent="s3"/>如果未为 Step 定义转换,则 Job 的状态定义如下
-
如果
Step以FAILED的ExitStatus结束,则Job的BatchStatus和ExitStatus都为FAILED。 -
否则,
Job的BatchStatus和ExitStatus都为COMPLETED。
虽然这种终止批处理 Job 的方法对于某些批处理 Job(例如简单的顺序步骤 Job)来说已经足够,但可能需要自定义的 Job 停止场景。为此,Spring Batch 提供了三个 transition 元素来停止 Job(除了我们之前讨论的next 元素之外)。这些停止元素中的每一个都以特定的 BatchStatus 停止 Job。重要的是要注意,停止 transition 元素对 Job 中任何 Steps 的 BatchStatus 或 ExitStatus 都没有影响。这些元素仅影响 Job 的最终状态。例如,Job 中的每个步骤都可能具有 FAILED 状态,但 Job 却具有 COMPLETED 状态。
在 Step 处结束
配置步骤结束会指示 Job 以 COMPLETED 的 BatchStatus 停止。状态为 COMPLETED 的 Job 不能重启(框架会抛出 JobInstanceAlreadyCompleteException 异常)。
-
Java
-
XML
使用 Java 配置时,end 方法用于此任务。end 方法还允许一个可选的 exitStatus 参数,你可以用它来自定义 Job 的 ExitStatus。如果未提供 exitStatus 值,则默认 ExitStatus 为 COMPLETED,以匹配 BatchStatus。
使用 XML 配置时,你可以使用 end 元素来完成此任务。end 元素还允许一个可选的 exit-code 属性,你可以用它来自定义 Job 的 ExitStatus。如果未给定 exit-code 属性,则默认 ExitStatus 为 COMPLETED,以匹配 BatchStatus。
考虑以下场景:如果 step2 失败,Job 将以 COMPLETED 的 BatchStatus 和 COMPLETED 的 ExitStatus 停止,并且 step3 不会运行。否则,执行将移至 step3。请注意,如果 step2 失败,该 Job 不可重启(因为状态是 COMPLETED)。
-
Java
-
XML
以下示例展示了 Java 中的场景
@Bean
public Job job(JobRepository jobRepository, Step step1, Step step2, Step step3) {
return new JobBuilder("job", jobRepository)
.start(step1)
.next(step2)
.on("FAILED").end()
.from(step2).on("*").to(step3)
.end()
.build();
}以下示例展示了 XML 中的场景
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<end on="FAILED"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">使 Step 失败
配置一个步骤在给定点失败会指示 Job 以 FAILED 的 BatchStatus 停止。与 end 不同的是,Job 的失败不会阻止 Job 重启。
使用 XML 配置时,fail 元素也允许一个可选的 exit-code 属性,可用于自定义 Job 的 ExitStatus。如果未给定 exit-code 属性,则默认 ExitStatus 为 FAILED,以匹配 BatchStatus。
考虑以下场景:如果 step2 失败,Job 将以 FAILED 的 BatchStatus 和 EARLY TERMINATION 的 ExitStatus 停止,并且 step3 不会执行。否则,执行将移至 step3。此外,如果 step2 失败并且 Job 被重启,执行将从 step2 重新开始。
-
Java
-
XML
以下示例展示了 Java 中的场景
@Bean
public Job job(JobRepository jobRepository, Step step1, Step step2, Step step3) {
return new JobBuilder("job", jobRepository)
.start(step1)
.next(step2).on("FAILED").fail()
.from(step2).on("*").to(step3)
.end()
.build();
}以下示例展示了 XML 中的场景
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<fail on="FAILED" exit-code="EARLY TERMINATION"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">在给定 Step 停止 Job
配置 Job 在特定步骤停止会指示 Job 以 STOPPED 的 BatchStatus 停止。停止 Job 可以为处理提供一个临时中断,以便操作员可以在重启 Job 之前采取一些行动。
-
Java
-
XML
使用 Java 配置时,stopAndRestart 方法需要一个 restart 属性,该属性指定 Job 重启时应从哪个步骤继续执行。
使用 XML 配置时,stop 元素需要一个 restart 属性,该属性指定 Job 重启时应从哪个步骤继续执行。
考虑以下场景:如果 step1 以 COMPLETE 结束,则 Job 停止。一旦重启,执行将从 step2 开始。
-
Java
-
XML
以下示例展示了 Java 中的场景
@Bean
public Job job(JobRepository jobRepository, Step step1, Step step2) {
return new JobBuilder("job", jobRepository)
.start(step1).on("COMPLETED").stopAndRestart(step2)
.end()
.build();
}以下列表显示了 XML 中的场景
<step id="step1" parent="s1">
<stop on="COMPLETED" restart="step2"/>
</step>
<step id="step2" parent="s2"/>程序化流程决策
在某些情况下,可能需要比 ExitStatus 更多信息来决定下一步要执行哪个步骤。在这种情况下,可以使用 JobExecutionDecider 来辅助决策,如下例所示
public class MyDecider implements JobExecutionDecider {
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
String status;
if (someCondition()) {
status = "FAILED";
}
else {
status = "COMPLETED";
}
return new FlowExecutionStatus(status);
}
}-
Java
-
XML
在以下示例中,使用 Java 配置时,实现 JobExecutionDecider 的 bean 直接传递给 next 调用
@Bean
public Job job(JobRepository jobRepository, MyDecider decider, Step step1, Step step2, Step step3) {
return new JobBuilder("job", jobRepository)
.start(step1)
.next(decider).on("FAILED").to(step2)
.from(decider).on("COMPLETED").to(step3)
.end()
.build();
}在以下示例 Job 配置中,decision 指定了要使用的决策器以及所有转换
<job id="job">
<step id="step1" parent="s1" next="decision" />
<decision id="decision" decider="decider">
<next on="FAILED" to="step2" />
<next on="COMPLETED" to="step3" />
</decision>
<step id="step2" parent="s2" next="step3"/>
<step id="step3" parent="s3" />
</job>
<beans:bean id="decider" class="com.MyDecider"/>拆分流程
迄今为止描述的所有场景都涉及一个按线性方式一次执行一个步骤的 Job。除了这种典型风格外,Spring Batch 还允许 Job 配置并行流程。
-
Java
-
XML
基于 Java 的配置允许你通过提供的构建器配置拆分。如下例所示,split 元素包含一个或多个 flow 元素,其中可以定义完全独立的流程。split 元素还可以包含任何前面讨论过的转换元素,例如 next 属性或 next、end 或 fail 元素。
@Bean
public Flow flow1(Step step1, Step step2) {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1)
.next(step2)
.build();
}
@Bean
public Flow flow2(Step step3) {
return new FlowBuilder<SimpleFlow>("flow2")
.start(step3)
.build();
}
@Bean
public Job job(JobRepository jobRepository, Flow flow1, Flow flow2, Step step4) {
return new JobBuilder("job", jobRepository)
.start(flow1)
.split(new SimpleAsyncTaskExecutor())
.add(flow2)
.next(step4)
.end()
.build();
}XML 命名空间允许你使用 split 元素。如下例所示,split 元素包含一个或多个 flow 元素,其中可以定义完全独立的流程。split 元素还可以包含任何前面讨论过的转换元素,例如 next 属性或 next、end 或 fail 元素。
<split id="split1" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>外部化流程定义和 Job 之间的依赖关系
Job 中的一部分流程可以作为单独的 bean 定义外部化,然后重新使用。有两种方法可以做到这一点。第一种是将流程声明为对其他地方定义的流程的引用。
-
Java
-
XML
以下 Java 示例展示了如何将流程声明为对其他地方定义的流程的引用
@Bean
public Job job(JobRepository jobRepository, Flow flow1, Step step3) {
return new JobBuilder("job", jobRepository)
.start(flow1)
.next(step3)
.end()
.build();
}
@Bean
public Flow flow1(Step step1, Step step2) {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1)
.next(step2)
.build();
}以下 XML 示例展示了如何将流程声明为对其他地方定义的流程的引用
<job id="job">
<flow id="job1.flow1" parent="flow1" next="step3"/>
<step id="step3" parent="s3"/>
</job>
<flow id="flow1">
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>如前例所示,定义外部流程的效果是将外部流程中的步骤插入到 Job 中,就像它们是内联声明的一样。通过这种方式,许多 Job 可以引用相同的模板流程,并将这些模板组合成不同的逻辑流程。这也是分离各个流程集成测试的好方法。
外部化流程的另一种形式是使用 JobStep。JobStep 类似于 FlowStep,但实际上会为指定流程中的步骤创建并启动一个单独的 Job 执行。
-
Java
-
XML
以下示例展示了 Java 中的 JobStep 示例
@Bean
public Job jobStepJob(JobRepository jobRepository, Step jobStepJobStep1) {
return new JobBuilder("jobStepJob", jobRepository)
.start(jobStepJobStep1)
.build();
}
@Bean
public Step jobStepJobStep1(JobRepository jobRepository, JobLauncher jobLauncher, Job job, JobParametersExtractor jobParametersExtractor) {
return new StepBuilder("jobStepJobStep1", jobRepository)
.job(job)
.launcher(jobLauncher)
.parametersExtractor(jobParametersExtractor)
.build();
}
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
// ...
.build();
}
@Bean
public DefaultJobParametersExtractor jobParametersExtractor() {
DefaultJobParametersExtractor extractor = new DefaultJobParametersExtractor();
extractor.setKeys(new String[]{"input.file"});
return extractor;
}以下示例展示了 XML 中的 JobStep 示例
<job id="jobStepJob" restartable="true">
<step id="jobStepJob.step1">
<job ref="job" job-launcher="jobLauncher"
job-parameters-extractor="jobParametersExtractor"/>
</step>
</job>
<job id="job" restartable="true">...</job>
<bean id="jobParametersExtractor" class="org.spr...DefaultJobParametersExtractor">
<property name="keys" value="input.file"/>
</bean>Job 参数提取器是一种策略,它决定了如何将 Step 的 ExecutionContext 转换为要运行的 Job 的 JobParameters。JobStep 在你想要对 Job 和步骤进行更细粒度的监控和报告时非常有用。使用 JobStep 也常常是回答“如何创建 Job 之间的依赖关系?”这个问题的好方法。它是将大型系统分解为更小模块并控制 Job 流程的好方法。

