常见批处理模式
一些批处理作业可以完全由 Spring Batch 中的现成组件组装而成。例如,可以配置 ItemReader 和 ItemWriter 实现来涵盖各种场景。然而,在大多数情况下,必须编写自定义代码。应用程序开发人员的主要 API 入口点是 Tasklet、ItemReader、ItemWriter 以及各种监听器接口。大多数简单的批处理作业可以使用 Spring Batch ItemReader 的现成输入,但通常情况下,处理和写入中存在需要开发人员实现 ItemWriter 或 ItemProcessor 的自定义问题。
在本章中,我们提供了一些自定义业务逻辑中常见模式的示例。这些示例主要以监听器接口为特色。需要注意的是,ItemReader 或 ItemWriter 也可以在适当的情况下实现监听器接口。
日志记录项处理和失败
一个常见的用例是需要对步骤中的错误进行特殊处理,逐项处理,例如记录到特殊通道或将记录插入数据库。面向块的 Step(由步骤工厂 bean 创建)允许用户通过简单的 ItemReadListener 处理读取错误,通过 ItemWriteListener 处理写入错误来实现此用例。以下代码片段演示了一个记录读取和写入失败的监听器
public class ItemFailureLoggerListener extends ItemListenerSupport {
private static Log logger = LogFactory.getLog("item.error");
public void onReadError(Exception ex) {
logger.error("Encountered error on read", e);
}
public void onWriteError(Exception ex, List<? extends Object> items) {
logger.error("Encountered error on write", ex);
}
}实现此监听器后,必须将其注册到步骤中。
-
Java
-
XML
以下示例展示了如何使用 Java 将监听器注册到步骤中
@Bean
public Step simpleStep(JobRepository jobRepository) {
return new StepBuilder("simpleStep", jobRepository)
...
.listener(new ItemFailureLoggerListener())
.build();
}以下示例展示了如何使用 XML 将监听器注册到步骤中
<step id="simpleStep">
...
<listeners>
<listener>
<bean class="org.example...ItemFailureLoggerListener"/>
</listener>
</listeners>
</step>如果您的监听器在 onError() 方法中执行任何操作,则它必须在将要回滚的事务内部。如果您需要在 onError() 方法内部使用事务性资源(例如数据库),请考虑为该方法添加声明性事务(有关详细信息,请参阅 Spring Core 参考指南),并将其传播属性设置为 REQUIRES_NEW。 |
出于业务原因手动停止作业
Spring Batch 通过 JobOperator 接口提供了一个 stop() 方法,但这实际上是供操作员使用的,而不是应用程序程序员。有时,从业务逻辑内部停止作业执行更方便或更有意义。
最简单的做法是抛出一个 RuntimeException(一个既不会无限重试也不会跳过的异常)。例如,可以使用自定义异常类型,如以下示例所示
public class PoisonPillItemProcessor<T> implements ItemProcessor<T, T> {
@Override
public T process(T item) throws Exception {
if (isPoisonPill(item)) {
throw new PoisonPillException("Poison pill detected: " + item);
}
return item;
}
}停止执行步骤的另一种简单方法是从 ItemReader 返回 null,如以下示例所示
public class EarlyCompletionItemReader implements ItemReader<T> {
private ItemReader<T> delegate;
public void setDelegate(ItemReader<T> delegate) { ... }
public T read() throws Exception {
T item = delegate.read();
if (isEndItem(item)) {
return null; // end the step here
}
return item;
}
}前面的示例实际上依赖于 CompletionPolicy 策略的默认实现,当要处理的项为 null 时,该策略会发出完成批处理的信号。可以通过 SimpleStepFactoryBean 实现更复杂的完成策略并将其注入到 Step 中。
-
Java
-
XML
以下示例展示了如何在 Java 中将完成策略注入到步骤中
@Bean
public Step simpleStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("simpleStep", jobRepository)
.<String, String>chunk(new SpecialCompletionPolicy(), transactionManager)
.reader(reader())
.writer(writer())
.build();
}以下示例展示了如何在 XML 中将完成策略注入到步骤中
<step id="simpleStep">
<tasklet>
<chunk reader="reader" writer="writer" commit-interval="10"
chunk-completion-policy="completionPolicy"/>
</tasklet>
</step>
<bean id="completionPolicy" class="org.example...SpecialCompletionPolicy"/>另一种方法是在 StepExecution 中设置一个标志,框架中的 Step 实现会在项处理之间检查该标志。为了实现此替代方案,我们需要访问当前的 StepExecution,这可以通过实现 StepListener 并将其注册到 Step 来实现。以下示例展示了一个设置标志的监听器
public class CustomItemWriter extends ItemListenerSupport implements StepListener {
private StepExecution stepExecution;
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution;
}
public void afterRead(Object item) {
if (isPoisonPill(item)) {
stepExecution.setTerminateOnly();
}
}
}当设置了标志时,默认行为是步骤抛出 JobInterruptedException。此行为可以通过 StepInterruptionPolicy 控制。然而,唯一的选择是抛出或不抛出异常,因此这总是作业的异常结束。
添加页脚记录
通常,当写入平面文件时,在所有处理完成后,必须将“页脚”记录附加到文件末尾。这可以通过 Spring Batch 提供的 FlatFileFooterCallback 接口实现。FlatFileFooterCallback(及其对应项 FlatFileHeaderCallback)是 FlatFileItemWriter 的可选属性,可以添加到项写入器中。
-
Java
-
XML
以下示例展示了如何在 Java 中使用 FlatFileHeaderCallback 和 FlatFileFooterCallback
@Bean
public FlatFileItemWriter<String> itemWriter(Resource outputResource) {
return new FlatFileItemWriterBuilder<String>()
.name("itemWriter")
.resource(outputResource)
.lineAggregator(lineAggregator())
.headerCallback(headerCallback())
.footerCallback(footerCallback())
.build();
}以下示例展示了如何在 XML 中使用 FlatFileHeaderCallback 和 FlatFileFooterCallback
<bean id="itemWriter" class="org.spr...FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator" ref="lineAggregator"/>
<property name="headerCallback" ref="headerCallback" />
<property name="footerCallback" ref="footerCallback" />
</bean>页脚回调接口只有一个方法,当需要写入页脚时调用,如以下接口定义所示
public interface FlatFileFooterCallback {
void writeFooter(Writer writer) throws IOException;
}写入摘要页脚
涉及页脚记录的一个常见要求是在输出过程中聚合信息,并将此信息附加到文件末尾。此页脚通常用作文件的摘要或提供校验和。
例如,如果批处理作业正在将 Trade 记录写入平面文件,并且要求将所有 Trades 的总金额放入页脚,则可以使用以下 ItemWriter 实现
public class TradeItemWriter implements ItemWriter<Trade>,
FlatFileFooterCallback {
private ItemWriter<Trade> delegate;
private BigDecimal totalAmount = BigDecimal.ZERO;
public void write(Chunk<? extends Trade> items) throws Exception {
BigDecimal chunkTotal = BigDecimal.ZERO;
for (Trade trade : items) {
chunkTotal = chunkTotal.add(trade.getAmount());
}
delegate.write(items);
// After successfully writing all items
totalAmount = totalAmount.add(chunkTotal);
}
public void writeFooter(Writer writer) throws IOException {
writer.write("Total Amount Processed: " + totalAmount);
}
public void setDelegate(ItemWriter delegate) {...}
}此 TradeItemWriter 存储一个 totalAmount 值,该值随着写入的每个 Trade 项的 amount 而增加。在处理完最后一个 Trade 后,框架调用 writeFooter,将 totalAmount 写入文件。请注意,write 方法使用了一个临时变量 chunkTotal,它存储了块中 Trade 金额的总和。这样做是为了确保,如果 write 方法中发生跳过,totalAmount 保持不变。只有在 write 方法结束时,一旦我们确定没有抛出异常,我们才更新 totalAmount。
为了调用 writeFooter 方法,必须将 TradeItemWriter(它实现了 FlatFileFooterCallback)作为 footerCallback 连接到 FlatFileItemWriter 中。
-
Java
-
XML
以下示例展示了如何在 Java 中连接 TradeItemWriter
@Bean
public TradeItemWriter tradeItemWriter() {
TradeItemWriter itemWriter = new TradeItemWriter();
itemWriter.setDelegate(flatFileItemWriter(null));
return itemWriter;
}
@Bean
public FlatFileItemWriter<String> flatFileItemWriter(Resource outputResource) {
return new FlatFileItemWriterBuilder<String>()
.name("itemWriter")
.resource(outputResource)
.lineAggregator(lineAggregator())
.footerCallback(tradeItemWriter())
.build();
}以下示例展示了如何在 XML 中连接 TradeItemWriter
<bean id="tradeItemWriter" class="..TradeItemWriter">
<property name="delegate" ref="flatFileItemWriter" />
</bean>
<bean id="flatFileItemWriter" class="org.spr...FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator" ref="lineAggregator"/>
<property name="footerCallback" ref="tradeItemWriter" />
</bean>到目前为止,TradeItemWriter 的编写方式只有在 Step 不可重新启动时才能正常工作。这是因为该类是有状态的(因为它存储了 totalAmount),但 totalAmount 未持久化到数据库。因此,在重新启动时无法检索。为了使此类可重新启动,应实现 ItemStream 接口以及 open 和 update 方法,如以下示例所示
public void open(ExecutionContext executionContext) {
if (executionContext.containsKey("total.amount") {
totalAmount = (BigDecimal) executionContext.get("total.amount");
}
}
public void update(ExecutionContext executionContext) {
executionContext.put("total.amount", totalAmount);
}update 方法在 ExecutionContext 对象持久化到数据库之前,将 totalAmount 的最新版本存储到 ExecutionContext。open 方法从 ExecutionContext 检索任何现有的 totalAmount,并将其用作处理的起点,允许 TradeItemWriter 在重新启动时从上次 Step 运行停止的地方继续。
驱动基于查询的 ItemReaders
在读写器章节中,讨论了使用分页的数据库输入。许多数据库供应商,例如 DB2,具有非常悲观的锁定策略,如果正在读取的表也需要被在线应用程序的其他部分使用,则可能会导致问题。此外,对超大数据集打开游标可能会导致某些供应商的数据库出现问题。因此,许多项目倾向于使用“驱动查询”方法读取数据。这种方法通过迭代键而不是需要返回的整个对象来工作,如下图所示
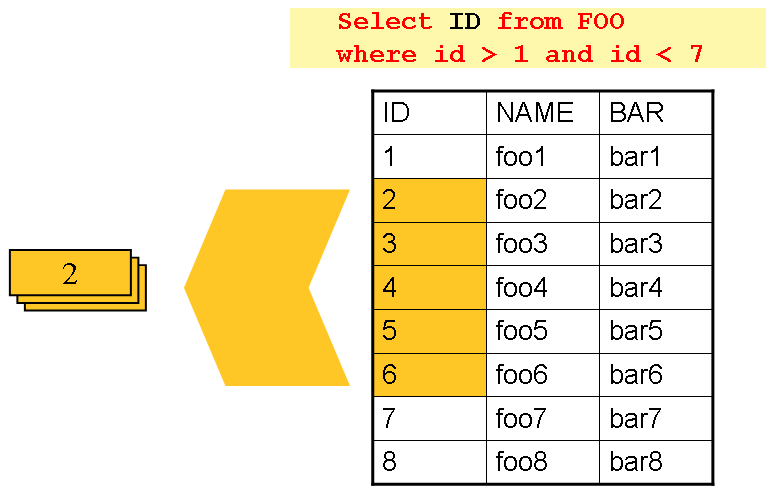
如您所见,前面图像中显示的示例使用了与基于游标的示例相同的“FOO”表。然而,在 SQL 语句中,只选择了 ID,而不是选择整个行。因此,从 read 返回的是一个 Integer,而不是一个 FOO 对象。然后,可以使用此数字查询“详细信息”,即一个完整的 Foo 对象,如下图所示
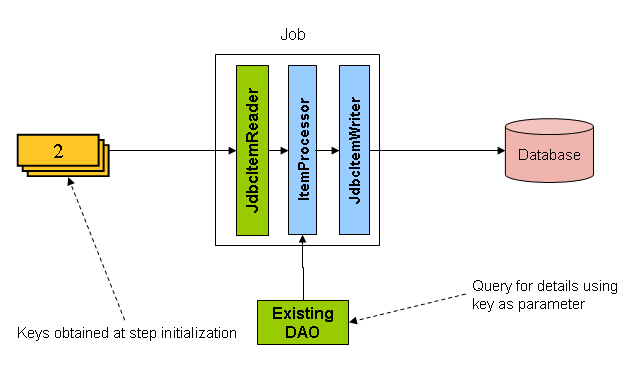
应使用 ItemProcessor 将从驱动查询获得的键转换为完整的 Foo 对象。可以使用现有 DAO 根据键查询完整的对象。
多行记录
虽然通常情况下,平面文件中的每条记录都限制在一行中,但文件可能包含跨多行且具有多种格式的记录。以下文件摘录显示了这种安排的一个示例
HEA;0013100345;2007-02-15 NCU;Smith;Peter;;T;20014539;F BAD;;Oak Street 31/A;;Small Town;00235;IL;US FOT;2;2;267.34
从“HEA”开头的行到“FOT”开头的行之间的所有内容都被视为一条记录。为了正确处理这种情况,必须考虑以下几点
-
ItemReader必须一次读取多行记录的所有行作为一个组,而不是一次读取一条记录,以便可以将其完整地传递给ItemWriter。 -
每种行类型可能需要以不同的方式进行标记。
由于一条记录跨越多行,并且我们可能不知道有多少行,因此 ItemReader 必须小心地始终读取整个记录。为此,应将自定义 ItemReader 实现为 FlatFileItemReader 的包装器。
-
Java
-
XML
以下示例展示了如何在 Java 中实现自定义 ItemReader
@Bean
public MultiLineTradeItemReader itemReader() {
MultiLineTradeItemReader itemReader = new MultiLineTradeItemReader();
itemReader.setDelegate(flatFileItemReader());
return itemReader;
}
@Bean
public FlatFileItemReader flatFileItemReader() {
FlatFileItemReader<Trade> reader = new FlatFileItemReaderBuilder<>()
.name("flatFileItemReader")
.resource(new ClassPathResource("data/iosample/input/multiLine.txt"))
.lineTokenizer(orderFileTokenizer())
.fieldSetMapper(orderFieldSetMapper())
.build();
return reader;
}以下示例展示了如何在 XML 中实现自定义 ItemReader
<bean id="itemReader" class="org.spr...MultiLineTradeItemReader">
<property name="delegate">
<bean class="org.springframework.batch.infrastructure.item.file.FlatFileItemReader">
<property name="resource" value="data/iosample/input/multiLine.txt" />
<property name="lineMapper">
<bean class="org.spr...DefaultLineMapper">
<property name="lineTokenizer" ref="orderFileTokenizer"/>
<property name="fieldSetMapper" ref="orderFieldSetMapper"/>
</bean>
</property>
</bean>
</property>
</bean>为了确保每行都正确分词(这对于固定长度输入尤其重要),可以在委托 FlatFileItemReader 上使用 PatternMatchingCompositeLineTokenizer。有关更多详细信息,请参阅读写器章节中的 FlatFileItemReader。然后,委托读取器使用 PassThroughFieldSetMapper 为每行向包装 ItemReader 提供一个 FieldSet。
-
Java
-
XML
以下示例展示了如何在 Java 中确保每行都被正确分词
@Bean
public PatternMatchingCompositeLineTokenizer orderFileTokenizer() {
PatternMatchingCompositeLineTokenizer tokenizer =
new PatternMatchingCompositeLineTokenizer();
Map<String, LineTokenizer> tokenizers = new HashMap<>(4);
tokenizers.put("HEA*", headerRecordTokenizer());
tokenizers.put("FOT*", footerRecordTokenizer());
tokenizers.put("NCU*", customerLineTokenizer());
tokenizers.put("BAD*", billingAddressLineTokenizer());
tokenizer.setTokenizers(tokenizers);
return tokenizer;
}以下示例展示了如何在 XML 中确保每行都被正确分词
<bean id="orderFileTokenizer" class="org.spr...PatternMatchingCompositeLineTokenizer">
<property name="tokenizers">
<map>
<entry key="HEA*" value-ref="headerRecordTokenizer" />
<entry key="FOT*" value-ref="footerRecordTokenizer" />
<entry key="NCU*" value-ref="customerLineTokenizer" />
<entry key="BAD*" value-ref="billingAddressLineTokenizer" />
</map>
</property>
</bean>此包装器必须能够识别记录的末尾,以便它可以不断地对其委托对象调用 read(),直到达到末尾。对于读取的每一行,包装器都应该构建要返回的项。一旦到达页脚,就可以返回该项以交付给 ItemProcessor 和 ItemWriter,如以下示例所示
private FlatFileItemReader<FieldSet> delegate;
public Trade read() throws Exception {
Trade t = null;
for (FieldSet line = null; (line = this.delegate.read()) != null;) {
String prefix = line.readString(0);
if (prefix.equals("HEA")) {
t = new Trade(); // Record must start with header
}
else if (prefix.equals("NCU")) {
Assert.notNull(t, "No header was found.");
t.setLast(line.readString(1));
t.setFirst(line.readString(2));
...
}
else if (prefix.equals("BAD")) {
Assert.notNull(t, "No header was found.");
t.setCity(line.readString(4));
t.setState(line.readString(6));
...
}
else if (prefix.equals("FOT")) {
return t; // Record must end with footer
}
}
Assert.isNull(t, "No 'END' was found.");
return null;
}执行系统命令
许多批处理作业要求从批处理作业内部调用外部命令。这样的过程可以由调度程序单独启动,但这样会丢失有关运行的公共元数据。此外,多步骤作业也需要拆分为多个作业。
由于此需求非常常见,Spring Batch 提供了一个用于调用系统命令的 Tasklet 实现。
-
Java
-
XML
以下示例展示了如何在 Java 中调用外部命令
@Bean
public SystemCommandTasklet tasklet() {
SystemCommandTasklet tasklet = new SystemCommandTasklet();
tasklet.setCommand("echo hello");
tasklet.setTimeout(5000);
return tasklet;
}以下示例展示了如何在 XML 中调用外部命令
<bean class="org.springframework.batch.core.step.tasklet.SystemCommandTasklet">
<property name="command" value="echo hello" />
<!-- 5 second timeout for the command to complete -->
<property name="timeout" value="5000" />
</bean>处理未找到输入时的步骤完成
在许多批处理场景中,在数据库或文件中找不到要处理的行并非异常。Step 只是被认为没有找到工作,并以读取 0 项完成。Spring Batch 中开箱即用的所有 ItemReader 实现都默认采用此方法。如果即使存在输入也没有写入任何内容(通常在文件命名错误或出现类似问题时发生),这可能会导致一些混乱。因此,应该检查元数据本身以确定框架发现了多少要处理的工作。但是,如果找不到输入被认为是异常情况怎么办?在这种情况下,程序化地检查元数据以确定没有处理任何项并导致失败是最佳解决方案。因为这是一个常见的用例,Spring Batch 提供了一个具有完全此功能的监听器,如 NoWorkFoundStepExecutionListener 的类定义所示
public class NoWorkFoundStepExecutionListener implements StepExecutionListener {
public ExitStatus afterStep(StepExecution stepExecution) {
if (stepExecution.getReadCount() == 0) {
return ExitStatus.FAILED;
}
return null;
}
}前面的 StepExecutionListener 在“afterStep”阶段检查 StepExecution 的 readCount 属性,以确定是否没有读取任何项。如果是这种情况,则返回退出代码 FAILED,表示 Step 应该失败。否则,返回 null,这不会影响 Step 的状态。
将数据传递给未来的步骤
将信息从一个步骤传递到另一个步骤通常很有用。这可以通过 ExecutionContext 完成。需要注意的是,有两个 ExecutionContext:一个在 Step 级别,一个在 Job 级别。Step 的 ExecutionContext 仅在步骤持续期间存在,而 Job 的 ExecutionContext 则在整个 Job 期间存在。另一方面,Step 的 ExecutionContext 在每次 Step 提交一个块时更新,而 Job 的 ExecutionContext 仅在每个 Step 结束时更新。
这种分离的结果是,所有数据都必须在 Step 执行期间放置在 Step ExecutionContext 中。这样做可以确保数据在 Step 运行时正确存储。如果数据存储在 Job ExecutionContext 中,则在 Step 执行期间不会持久化。如果 Step 失败,这些数据将丢失。
public class SavingItemWriter implements ItemWriter<Object> {
private StepExecution stepExecution;
public void write(Chunk<? extends Object> items) throws Exception {
// ...
ExecutionContext stepContext = this.stepExecution.getExecutionContext();
stepContext.put("someKey", someObject);
}
@BeforeStep
public void saveStepExecution(StepExecution stepExecution) {
this.stepExecution = stepExecution;
}
}为了使数据可供未来的 Steps 使用,它必须在步骤完成后“提升”到 Job ExecutionContext。Spring Batch 为此提供了 ExecutionContextPromotionListener。监听器必须配置与 ExecutionContext 中必须提升的数据相关的键。它还可以选择配置一个退出代码模式列表,在此模式下应发生提升(COMPLETED 是默认值)。与所有监听器一样,它必须在 Step 上注册。
-
Java
-
XML
以下示例展示了如何在 Java 中将步骤提升到 Job ExecutionContext
@Bean
public Job job1(JobRepository jobRepository, Step step1, Step step2) {
return new JobBuilder("job1", jobRepository)
.start(step1)
.next(step2)
.build();
}
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.<String, String>chunk(10).transactionManager(transactionManager)
.reader(reader())
.writer(savingWriter())
.listener(promotionListener())
.build();
}
@Bean
public ExecutionContextPromotionListener promotionListener() {
ExecutionContextPromotionListener listener = new ExecutionContextPromotionListener();
listener.setKeys(new String[] {"someKey"});
return listener;
}以下示例展示了如何在 XML 中将步骤提升到 Job ExecutionContext
<job id="job1">
<step id="step1">
<tasklet>
<chunk reader="reader" writer="savingWriter" commit-interval="10"/>
</tasklet>
<listeners>
<listener ref="promotionListener"/>
</listeners>
</step>
<step id="step2">
...
</step>
</job>
<beans:bean id="promotionListener" class="org.spr....ExecutionContextPromotionListener">
<beans:property name="keys">
<list>
<value>someKey</value>
</list>
</beans:property>
</beans:bean>最后,必须从 Job ExecutionContext 中检索保存的值,如以下示例所示
public class RetrievingItemWriter implements ItemWriter<Object> {
private Object someObject;
public void write(Chunk<? extends Object> items) throws Exception {
// ...
}
@BeforeStep
public void retrieveInterstepData(StepExecution stepExecution) {
JobExecution jobExecution = stepExecution.getJobExecution();
ExecutionContext jobContext = jobExecution.getExecutionContext();
this.someObject = jobContext.get("someKey");
}
}
