Spring 数据集成之旅的简史
Spring 在数据集成方面的旅程始于 Spring Integration。凭借其编程模型,它提供了统一的开发体验,用于构建能够采用 企业集成模式 的应用程序,以连接到外部系统,例如数据库、消息代理等。
快进到云时代,微服务在企业环境中变得突出。Spring Boot 改变了开发人员构建应用程序的方式。凭借 Spring 的编程模型和 Spring Boot 处理的运行时职责,开发独立的、生产级的基于 Spring 的微服务变得无缝。
为了将其扩展到数据集成工作负载,Spring Integration 和 Spring Boot 被组合到一个新项目中。Spring Cloud Stream 诞生了。
使用 Spring Cloud Stream,开发人员可以
-
独立构建、测试和部署以数据为中心的应用程序。
-
应用现代微服务架构模式,包括通过消息传递进行组合。
-
通过以事件为中心的思维解耦应用程序职责。事件可以表示在时间上发生的事情,下游消费者应用程序可以对其做出反应,而无需知道它的来源或生产者的身份。
-
将业务逻辑移植到消息代理(如 RabbitMQ、Apache Kafka、Amazon Kinesis)。
-
依靠框架的自动内容类型支持来处理常见用例。扩展到不同的数据转换类型是可能的。
-
等等。
快速入门
您可以按照此三步指南,在不到 5 分钟的时间内尝试 Spring Cloud Stream,甚至在您深入了解任何细节之前。
我们将向您展示如何创建一个 Spring Cloud Stream 应用程序,该应用程序接收来自您选择的消息中间件(稍后详述)的消息,并将接收到的消息记录到控制台。我们称之为 LoggingConsumer。虽然不实用,但它很好地介绍了 Spring Cloud Stream 的一些主要概念和抽象,使其更容易理解本用户指南的其余部分。
这三个步骤如下:
使用 Spring Initializr 创建示例应用程序
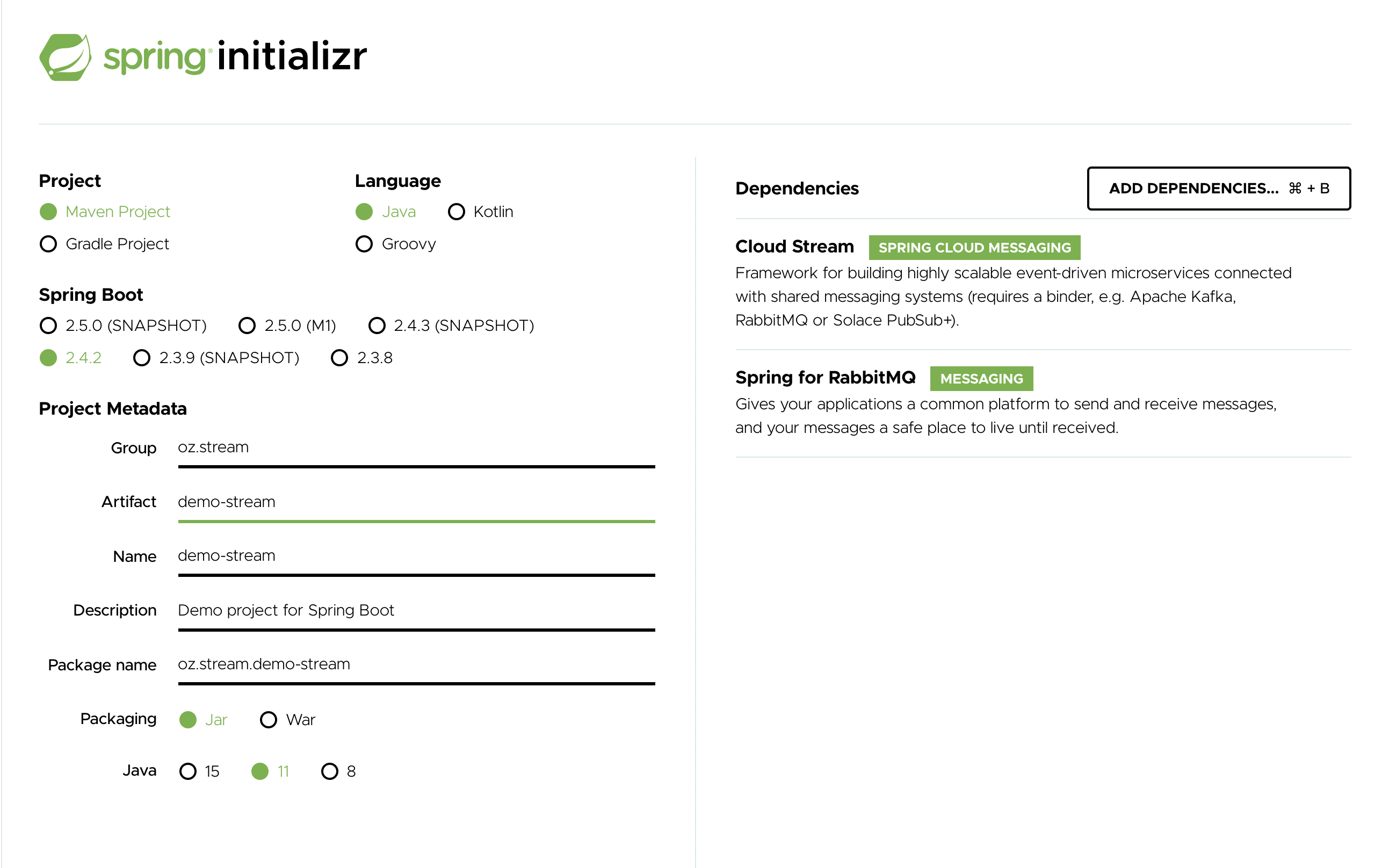
首先,访问 Spring Initializr。从那里,您可以生成我们的 LoggingConsumer 应用程序。要这样做
-
在 依赖项 部分,开始键入
stream。当出现“Cloud Stream”选项时,选择它。 -
开始键入“kafka”或“rabbit”。
-
选择“Kafka”或“RabbitMQ”。
基本上,您选择应用程序绑定的消息中间件。我们建议使用您已经安装或更喜欢安装和运行的那个。此外,从 Initializr 屏幕上您可以看到,还有一些其他选项可供选择。例如,您可以选择 Gradle 作为构建工具而不是 Maven(默认)。
-
在 Artifact 字段中,键入 'logging-consumer'。
Artifact 字段的值成为应用程序名称。如果您选择 RabbitMQ 作为中间件,您的 Spring Initializr 现在应该如下所示
-
点击 生成项目 按钮。
这样做会将生成的项目的压缩版本下载到您的硬盘。
-
将文件解压缩到您要用作项目目录的文件夹中。
| 我们鼓励您探索 Spring Initializr 中可用的许多可能性。它允许您创建许多不同类型的 Spring 应用程序。 |
将项目导入您的 IDE
现在您可以将项目导入您的 IDE。请记住,根据 IDE 的不同,您可能需要遵循特定的导入过程。例如,根据项目生成方式(Maven 或 Gradle),您可能需要遵循特定的导入过程(例如,在 Eclipse 或 STS 中,您需要使用文件 → 导入 → Maven → 现有 Maven 项目)。
导入后,项目不得有任何类型的错误。此外,src/main/java 应该包含 com.example.loggingconsumer.LoggingConsumerApplication。
从技术上讲,此时您可以运行应用程序的主类。它已经是有效的 Spring Boot 应用程序。但是,它不做任何事情,所以我们想添加一些代码。
添加消息处理程序、构建和运行
修改 com.example.loggingconsumer.LoggingConsumerApplication 类,使其看起来如下所示
@SpringBootApplication
public class LoggingConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(LoggingConsumerApplication.class, args);
}
@Bean
public Consumer<Person> log() {
return person -> {
System.out.println("Received: " + person);
};
}
public static class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return this.name;
}
}
}从前面的列表中可以看出
-
我们使用函数式编程模型(参见 [Spring Cloud Function support])将单个消息处理程序定义为
Consumer。 -
我们依赖框架约定将此类处理程序绑定到由绑定器公开的输入目标绑定。
这样做还可以让您看到框架的一个核心功能:它尝试自动将传入消息负载转换为 Person 类型。
您现在拥有一个功能齐全的 Spring Cloud Stream 应用程序,它侦听消息。为了简单起见,我们假设您在 第一步 中选择了 RabbitMQ。假设您已安装并运行 RabbitMQ,您可以通过在 IDE 中运行其 main 方法来启动应用程序。
您应该会看到以下输出
--- [ main] c.s.b.r.p.RabbitExchangeQueueProvisioner : declaring queue for inbound: input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg, bound to: input
--- [ main] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: [localhost:5672]
--- [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: rabbitConnectionFactory#2a3a299:0/SimpleConnection@66c83fc8. . .
. . .
--- [ main] o.s.i.a.i.AmqpInboundChannelAdapter : started inbound.input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg
. . .
--- [ main] c.e.l.LoggingConsumerApplication : Started LoggingConsumerApplication in 2.531 seconds (JVM running for 2.897)转到 RabbitMQ 管理控制台或任何其他 RabbitMQ 客户端,并向 input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg 发送消息。anonymous.CbMIwdkJSBO1ZoPDOtHtCg 部分表示组名,它是生成的,因此在您的环境中必然不同。为了更具可预测性,您可以通过设置 spring.cloud.stream.bindings.input.group=hello(或任何您喜欢的名称)来使用显式组名。
消息的内容应该是 Person 类的 JSON 表示,如下所示
{"name":"Sam Spade"}
然后,在您的控制台中,您应该会看到
收到:Sam Spade
您还可以将应用程序构建并打包成一个引导 JAR(使用 ./mvnw clean install),然后使用 java -jar 命令运行构建的 JAR。
现在您有了一个正在运行的(尽管非常基础的)Spring Cloud Stream 应用程序。
流数据上下文中的 Spring 表达式语言 (SpEL)
在整个参考手册中,您将遇到许多可以利用 Spring 表达式语言 (SpEL) 的功能和示例。理解使用它时某些限制是很重要的。
SpEL 允许您访问当前消息以及您正在运行的应用程序上下文。但是,重要的是要了解 SpEL 可以看到的数据类型,尤其是在传入消息的上下文中。从代理,消息以 byte[] 的形式到达。然后,它由绑定器转换为 Message<byte[]>,而您可以看到消息的有效负载保持其原始形式。消息的标头是 <String, Object>,其中值通常是另一个原始类型或原始类型的集合/数组,因此是 Object。这是因为绑定器不知道所需的输入类型,因为它无法访问用户代码(函数)。所以,实际上绑定器传递了一个带有有效负载和一些可读元数据(以消息标头形式)的信封,就像通过邮件递送的信件一样。这意味着,虽然可以访问消息的有效负载,但您只能将其作为原始数据(即 byte[])访问。而且,虽然开发人员可能经常要求 SpEL 能够以具体类型(例如 Foo、Bar 等)访问有效负载对象的字段,但您可以看到实现起来有多么困难甚至不可能。这里有一个示例来演示这个问题;想象一下您有一个路由表达式,根据有效负载类型路由到不同的函数。这个要求意味着有效负载从 byte[] 转换为特定类型,然后应用 SpEL。但是,为了执行这种转换,我们需要知道要传递给转换器的实际类型,而这来自函数的签名,我们不知道是哪个函数。解决此要求的一个更好的方法是将类型信息作为消息标头传递(例如,application/json;type=foo.bar.Baz)。您将获得一个清晰可读的字符串值,可以在一年中轻松访问和评估,并且易于阅读的 SpEL 表达式。
此外,将有效负载用于路由决策被认为是非常糟糕的做法,因为有效负载被认为是特权数据——只有其最终接收者才能读取的数据。同样,以邮件递送类比,您不会希望邮递员打开您的信封并阅读信件内容以做出一些递送决策。同样的道理也适用于这里,尤其是在生成消息时包含此类信息相对容易的情况下。它强制执行与通过网络传输的数据设计相关的特定级别的纪律,以及这些数据中哪些部分可以被视为公开的,哪些是特权的。

