4.0.5
前言
Spring 数据集成之旅的简史
Spring 的数据集成之旅始于 Spring Integration。凭借其编程模型,它提供了始终如一的开发人员体验,以构建可以采用 企业集成模式 来连接外部系统(例如数据库、消息代理等)的应用程序。
快进到云时代,微服务在企业环境中变得突出。Spring Boot 改变了开发人员构建应用程序的方式。凭借 Spring 的编程模型和 Spring Boot 处理的运行时职责,开发独立的、生产级的基于 Spring 的微服务变得无缝。
为了将此扩展到数据集成工作负载,Spring Integration 和 Spring Boot 被组合成一个新项目。Spring Cloud Stream 应运而生。
使用 Spring Cloud Stream,开发人员可以
-
独立构建、测试和部署以数据为中心的应用程序。
-
应用现代微服务架构模式,包括通过消息传递进行组合。
-
通过以事件为中心的思维解耦应用程序职责。事件可以表示在特定时间发生的事情,下游消费者应用程序可以对其做出反应,而无需知道其来源或生产者的身份。
-
将业务逻辑移植到消息代理(如 RabbitMQ、Apache Kafka、Amazon Kinesis)。
-
依赖框架对常见用例的自动内容类型支持。可以扩展到不同的数据转换类型。
-
以及更多。。。
快速入门
您可以通过遵循此三步指南,在不到 5 分钟的时间内尝试 Spring Cloud Stream,甚至在深入了解任何细节之前。
我们向您展示如何创建一个 Spring Cloud Stream 应用程序,该应用程序接收来自您选择的消息中间件(稍后会详细介绍)的消息,并将接收到的消息记录到控制台。我们称之为 LoggingConsumer。虽然不实用,但它很好地介绍了它的一些主要概念和抽象,使消化本用户指南的其余部分变得更容易。
这三个步骤如下:
使用 Spring Initializr 创建示例应用程序
要开始,请访问 Spring Initializr。从那里,您可以生成我们的 LoggingConsumer 应用程序。为此
-
在Dependencies 部分,开始输入
stream。当出现“Cloud Stream”选项时,选择它。 -
开始输入“kafka”或“rabbit”。
-
选择“Kafka”或“RabbitMQ”。
基本上,您选择应用程序绑定的消息中间件。我们建议使用您已安装或更喜欢安装和运行的那个。此外,正如您从 Initilaizer 屏幕中看到的,还有其他一些选项可供选择。例如,您可以选择 Gradle 作为构建工具而不是 Maven(默认)。
-
在Artifact 字段中,输入 'logging-consumer'。
Artifact 字段的值成为应用程序名称。如果您选择 RabbitMQ 作为中间件,您的 Spring Initializr 现在应该如下所示
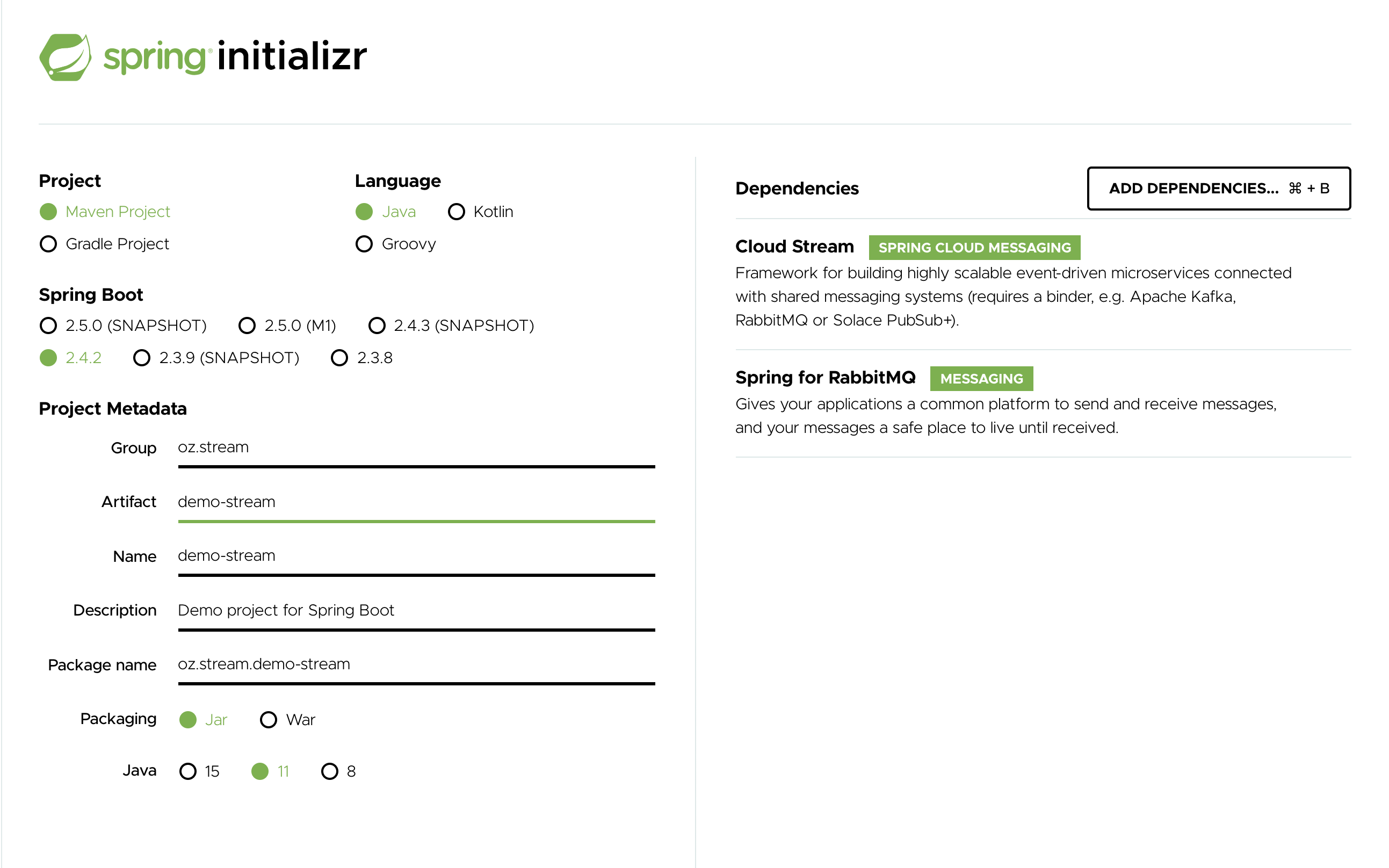
-
单击Generate Project 按钮。
这样做会将生成的项目的压缩版本下载到您的硬盘。
-
将文件解压到您要用作项目目录的文件夹中。
| 我们鼓励您探索 Spring Initializr 中提供的许多可能性。它允许您创建许多不同类型的 Spring 应用程序。 |
将项目导入到 IDE
现在您可以将项目导入到 IDE 中。请记住,根据 IDE 的不同,您可能需要遵循特定的导入过程。例如,根据项目生成方式(Maven 或 Gradle),您可能需要遵循特定的导入过程(例如,在 Eclipse 或 STS 中,您需要使用 File → Import → Maven → Existing Maven Project)。
导入后,项目不得有任何错误。此外,src/main/java 应该包含 com.example.loggingconsumer.LoggingConsumerApplication。
从技术上讲,此时您可以运行应用程序的主类。它已经是有效的 Spring Boot 应用程序。但是,它什么都不做,所以我们想添加一些代码。
添加消息处理程序、构建和运行
修改 com.example.loggingconsumer.LoggingConsumerApplication 类,使其看起来如下所示
@SpringBootApplication
public class LoggingConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(LoggingConsumerApplication.class, args);
}
@Bean
public Consumer<Person> log() {
return person -> {
System.out.println("Received: " + person);
};
}
public static class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return this.name;
}
}
}
从前面的列表中可以看到
-
我们使用函数式编程模型(参见 Spring Cloud Function 支持)将单个消息处理程序定义为
Consumer。 -
我们依赖框架约定将此类处理程序绑定到绑定器公开的输入目标绑定。
这样做还让您可以看到框架的核心功能之一:它尝试自动将传入消息负载转换为 Person 类型。
您现在有一个功能齐全的 Spring Cloud Stream 应用程序,它侦听消息。为简单起见,我们假设您在 第一步 中选择了 RabbitMQ。假设您已安装并运行 RabbitMQ,您可以通过在 IDE 中运行其 main 方法来启动应用程序。
您应该看到以下输出
--- [ main] c.s.b.r.p.RabbitExchangeQueueProvisioner : declaring queue for inbound: input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg, bound to: input
--- [ main] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: [localhost:5672]
--- [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: rabbitConnectionFactory#2a3a299:0/SimpleConnection@66c83fc8. . .
. . .
--- [ main] o.s.i.a.i.AmqpInboundChannelAdapter : started inbound.input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg
. . .
--- [ main] c.e.l.LoggingConsumerApplication : Started LoggingConsumerApplication in 2.531 seconds (JVM running for 2.897)转到 RabbitMQ 管理控制台或任何其他 RabbitMQ 客户端,并向 input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg 发送一条消息。anonymous.CbMIwdkJSBO1ZoPDOtHtCg 部分表示组名并是生成的,因此在您的环境中它肯定会有所不同。为了更具可预测性,您可以通过设置 spring.cloud.stream.bindings.input.group=hello(或您喜欢的任何名称)来使用显式组名。
消息的内容应该是 Person 类的 JSON 表示,如下所示
{"name":"Sam Spade"}
然后,在您的控制台中,您应该会看到
收到:山姆·斯佩德
您还可以将应用程序构建并打包成一个引导 jar(使用 ./mvnw clean install),然后使用 java -jar 命令运行构建好的 JAR。
现在您有了一个正在运行的(尽管非常基本)Spring Cloud Stream 应用程序。
流数据上下文中的 Spring Expression Language (SpEL)
在整个参考手册中,您将遇到许多可以使用 Spring Expression Language (SpEL) 的功能和示例。理解使用它时的某些限制很重要。
SpEL 允许您访问当前消息以及您正在运行的应用程序上下文。但是,了解 SpEL 可以看到的数据类型很重要,尤其是在传入消息的上下文中。从代理,消息以字节数组的形式到达。然后由绑定器将其转换为 Message<byte[]>,您可以看到消息的有效负载保持其原始形式。消息的头是 <String, Object>,其中值通常是另一个原始类型或原始类型的集合/数组,因此是 Object。这是因为绑定器不知道所需的输入类型,因为它无法访问用户代码(函数)。因此,绑定器有效地传递了一个带有有效负载和一些可读元数据(以消息头的形式)的信封,就像通过邮件发送的信件一样。这意味着虽然可以访问消息的有效负载,但您只能将其作为原始数据(即字节数组)访问。虽然开发人员要求 SpEL 访问有效负载对象的字段作为具体类型(例如 Foo、Bar 等)可能很常见,但您可以看到实现起来有多么困难甚至不可能。这里有一个示例来演示这个问题;想象一下您有一个路由表达式,根据有效负载类型路由到不同的函数。这个要求意味着有效负载从字节数组转换为特定类型,然后应用 SpEL。但是,为了执行这种转换,我们需要知道要传递给转换器的实际类型,而这来自函数签名,我们不知道是哪个。解决此要求的更好方法是将类型信息作为消息头传递(例如,application/json;type=foo.bar.Baz)。您将获得一个清晰可读的字符串值,可以在一年内访问和评估,并且易于阅读的 SpEL 表达式。
此外,将负载用于路由决策被认为是非常糟糕的做法,因为负载被认为是特权数据——只有其最终接收者才能读取的数据。同样,使用邮件投递类比,您不会希望邮递员打开您的信封并阅读信件内容以做出某些投递决策。同样的原则也适用于此处,尤其是在生成消息时包含此类信息相对容易的情况下。它强制执行与通过网络传输数据设计相关的某种程度的纪律,以及哪些数据部分可以被视为公开的,哪些是特权数据。
Spring Cloud Stream 简介
Spring Cloud Stream 是一个用于构建消息驱动微服务应用程序的框架。Spring Cloud Stream 构建于 Spring Boot 之上,用于创建独立的、生产级的 Spring 应用程序,并使用 Spring Integration 提供与消息代理的连接。它提供了多种供应商中间件的规范配置,引入了持久发布-订阅语义、消费者组和分区等概念。
通过将 spring-cloud-stream 依赖项添加到应用程序的类路径中,您可以立即连接到所提供的 spring-cloud-stream 绑定器公开的消息代理(稍后会详细介绍),并且您可以实现您的功能需求,该需求由 java.util.function.Function(根据传入消息)运行。
以下列表显示了一个快速示例
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}
以下列表显示了相应的测试
@SpringBootTest(classes = SampleApplication.class)
@Import({TestChannelBinderConfiguration.class})
class BootTestStreamApplicationTests {
@Autowired
private InputDestination input;
@Autowired
private OutputDestination output;
@Test
void contextLoads() {
input.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(output.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
}
主要概念
Spring Cloud Stream 提供了许多抽象和原语,可以简化消息驱动微服务应用程序的编写。本节概述以下内容
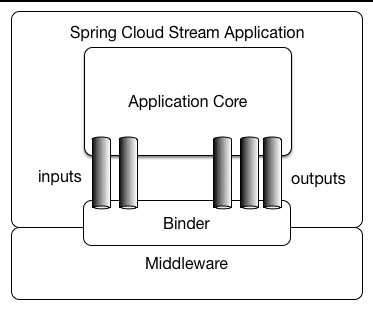
应用程序模型
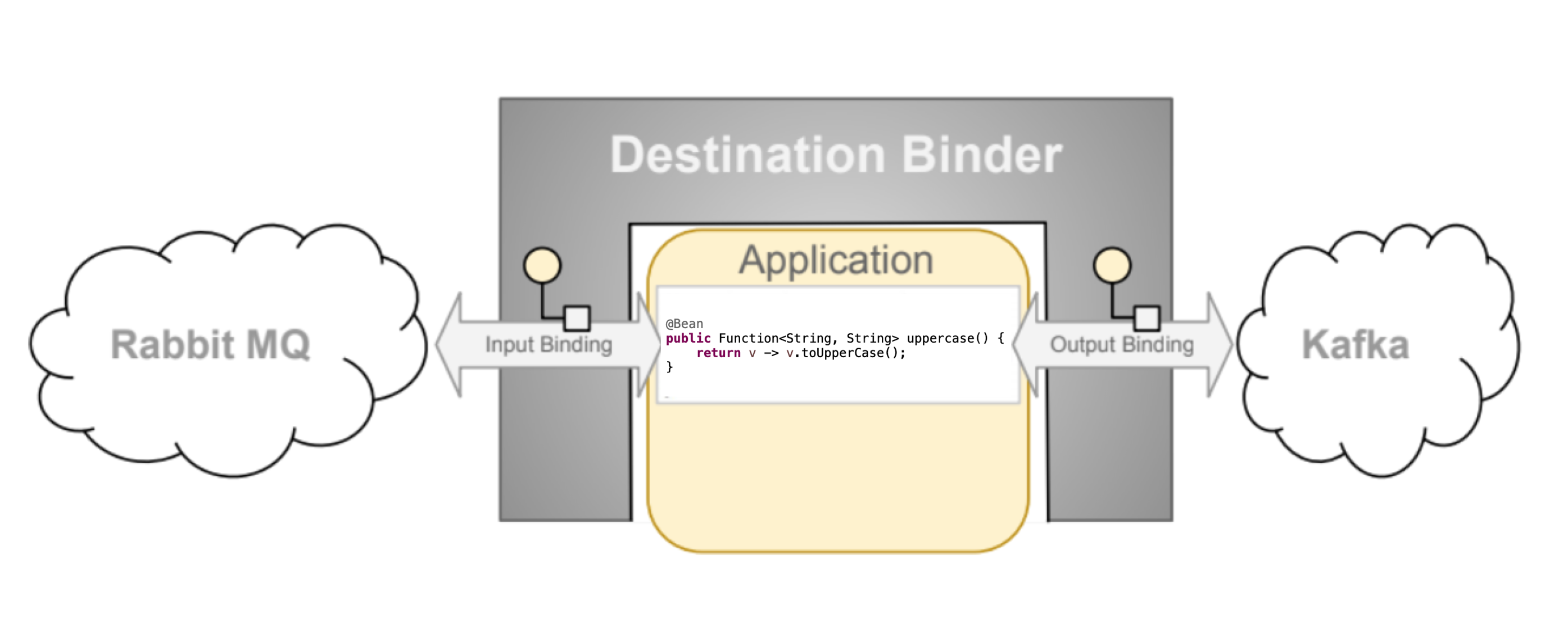
一个 Spring Cloud Stream 应用程序由一个与中间件无关的核心组成。应用程序通过在外部代理公开的目标和代码中的输入/输出参数之间建立绑定来与外部世界通信。建立绑定所需的代理特定细节由中间件特定的绑定器实现处理。
Fat JAR
Spring Cloud Stream 应用程序可以从您的 IDE 以独立模式运行进行测试。要在生产环境中运行 Spring Cloud Stream 应用程序,您可以使用 Maven 或 Gradle 提供的标准 Spring Boot 工具创建可执行(或“fat”)JAR。有关详细信息,请参阅 Spring Boot 参考指南。
绑定器抽象
Spring Cloud Stream 为 Kafka 和 Rabbit MQ 提供了 Binder 实现。该框架还包括一个测试绑定器,用于将您的应用程序作为 spring-cloud-stream 应用程序进行集成测试。有关详细信息,请参阅 测试 部分。
Binder 抽象也是框架的扩展点之一,这意味着您可以在 Spring Cloud Stream 之上实现自己的 Binder。在 How to create a Spring Cloud Stream Binder from scratch 一文中,社区成员详细记录了实现自定义 Binder 所需的步骤,并附带了一个示例。这些步骤也在 实现自定义绑定器 部分中突出显示。
Spring Cloud Stream 使用 Spring Boot 进行配置,Binder 抽象使 Spring Cloud Stream 应用程序能够灵活地连接到中间件。例如,部署人员可以在运行时动态选择外部目标(如 Kafka 主题或 RabbitMQ 交换机)与消息处理程序(如函数的输入参数及其返回参数)的输入和输出之间的映射。此类配置可以通过外部配置属性以及 Spring Boot 支持的任何形式(包括应用程序参数、环境变量和 application.yml 或 application.properties 文件)提供。在 Spring Cloud Stream 简介 部分的 sink 示例中,将 spring.cloud.stream.bindings.input.destination 应用程序属性设置为 raw-sensor-data 会使其从 raw-sensor-data Kafka 主题或绑定到 raw-sensor-data RabbitMQ 交换机的队列中读取。
Spring Cloud Stream 自动检测并使用类路径上找到的绑定器。您可以使用相同的代码处理不同类型的中间件。为此,请在构建时包含不同的绑定器。对于更复杂的用例,您还可以将多个绑定器与应用程序一起打包,并在运行时让它选择绑定器(甚至为不同的绑定使用不同的绑定器)。
持久发布-订阅支持
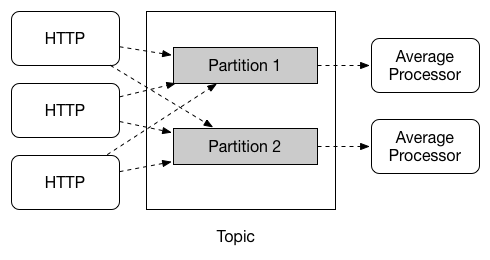
应用程序之间的通信遵循发布-订阅模型,数据通过共享主题广播。这可以在下图中看到,它显示了一组交互式 Spring Cloud Stream 应用程序的典型部署。
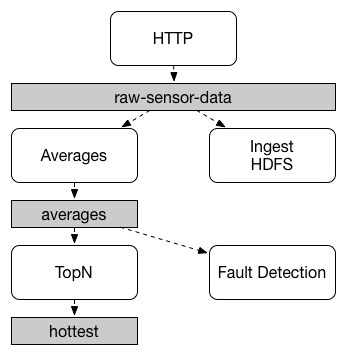
传感器向 HTTP 端点报告的数据被发送到一个名为 raw-sensor-data 的公共目的地。从该目的地,它由一个计算时间窗平均值的微服务应用程序和一个将原始数据摄取到 HDFS(Hadoop 分布式文件系统)的另一个微服务应用程序独立处理。为了处理数据,这两个应用程序在运行时都将该主题声明为它们的输入。
发布-订阅通信模型降低了生产者和消费者的复杂性,并允许将新应用程序添加到拓扑中而不会中断现有流。例如,在平均值计算应用程序的下游,您可以添加一个应用程序来计算要显示和监控的最高温度值。然后,您可以添加另一个应用程序来解释相同的平均值流以进行故障检测。通过共享主题而不是点对点队列进行所有通信减少了微服务之间的耦合。
虽然发布-订阅消息传递的概念并不新鲜,但 Spring Cloud Stream 进一步将其作为其应用程序模型的首选。通过使用原生中间件支持,Spring Cloud Stream 还简化了跨不同平台使用发布-订阅模型。
消费者组
虽然发布-订阅模型使通过共享主题连接应用程序变得容易,但通过创建给定应用程序的多个实例来扩展同样重要。这样做时,应用程序的不同实例被放置在竞争消费者关系中,其中只有一个实例有望处理给定消息。
Spring Cloud Stream 通过消费者组的概念来建模这种行为。(Spring Cloud Stream 消费者组与 Kafka 消费者组相似并受其启发。)每个消费者绑定都可以使用 spring.cloud.stream.bindings.<bindingName>.group 属性指定一个组名。对于下图中所示的消费者,此属性将设置为 spring.cloud.stream.bindings.<bindingName>.group=hdfsWrite 或 spring.cloud.stream.bindings.<bindingName>.group=average。
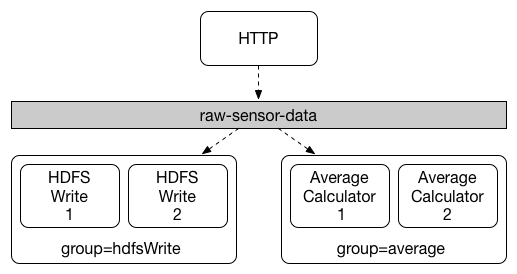
所有订阅给定目标的组都会收到发布数据的一份副本,但每个组中只有一个成员从该目标接收给定消息。默认情况下,当未指定组时,Spring Cloud Stream 会将应用程序分配给一个匿名且独立的单成员消费者组,该组与所有其他消费者组处于发布-订阅关系。
消费者类型
支持两种类型的消费者
-
消息驱动(有时称为异步)
-
轮询(有时称为同步)
在 2.0 版本之前,只支持异步消费者。消息一可用,且线程可用,就会立即传递。
当您希望控制消息处理速率时,您可能需要使用同步消费者。
持久性
与 Spring Cloud Stream 的规范应用程序模型一致,消费者组订阅是持久的。也就是说,绑定器实现确保组订阅是持久的,并且一旦为一个组创建了至少一个订阅,即使所有组中的应用程序都已停止,该组也会接收消息。
|
匿名订阅本质上是非持久的。对于某些绑定器实现(如 RabbitMQ),可以拥有非持久组订阅。 |
通常,在将应用程序绑定到给定目标时,最好始终指定一个消费者组。在扩展 Spring Cloud Stream 应用程序时,您必须为其每个输入绑定指定一个消费者组。这样做可以防止应用程序实例接收重复消息(除非需要这种行为,这很不寻常)。
分区支持
Spring Cloud Stream 支持在给定应用程序的多个实例之间进行数据分区。在分区场景中,物理通信介质(例如代理主题)被视为被构造成多个分区。一个或多个生产者应用程序实例向多个消费者应用程序实例发送数据,并确保由共同特征标识的数据由相同的消费者实例处理。
Spring Cloud Stream 提供了一个通用抽象,以统一的方式实现分区处理用例。因此,无论代理本身是否自然分区(例如 Kafka)或不分区(例如 RabbitMQ),都可以使用分区。
分区是有状态处理中的一个关键概念,在有状态处理中,确保所有相关数据一起处理至关重要(出于性能或一致性原因)。例如,在时间窗平均值计算示例中,任何给定传感器的所有测量值都必须由相同的应用程序实例处理。
| 要设置分区处理场景,您必须同时配置数据生产端和数据消费端。 |
编程模型
要理解编程模型,您应该熟悉以下核心概念
-
目标绑定器:负责提供与外部消息系统集成的组件。
-
绑定:外部消息系统与应用程序提供的消息生产者和消费者之间的桥梁(由目标绑定器创建)。
-
消息:生产者和消费者用于与目标绑定器(并通过外部消息系统与其他应用程序)通信的规范数据结构。
目标绑定器
目标绑定器是 Spring Cloud Stream 的扩展组件,负责提供必要的配置和实现,以促进与外部消息系统的集成。这种集成负责连接、消息到生产者和消费者之间的委托和路由、数据类型转换、用户代码调用等。
绑定器处理了许多原本会落在您肩上的样板职责。但是,为了实现这一点,绑定器仍然需要用户提供一些帮助,以最少但必需的指令集的形式,这些指令通常以某种绑定配置的形式出现。
虽然本节超出范围,无法讨论所有可用的绑定器和绑定配置选项(手册的其余部分广泛涵盖了它们),但绑定作为一个概念确实需要特别注意。下一节将详细讨论它。
绑定
如前所述,绑定提供了外部消息系统(例如,队列、主题等)与应用程序提供的生产者和消费者之间的桥梁。
以下示例显示了一个完全配置和运行的 Spring Cloud Stream 应用程序,该应用程序以 String 类型接收消息负载(参见 内容类型协商 部分),将其记录到控制台并在将其转换为大写后将其发送到下游。
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> {
System.out.println("Received: " + value);
return value.toUpperCase();
};
}
}
上述示例与任何普通的 Spring Boot 应用程序没有什么不同。它定义了一个 Function 类型的单个 bean,仅此而已。那么,它是如何成为 Spring Cloud Stream 应用程序的呢?它成为 Spring Cloud Stream 应用程序仅仅是因为类路径上存在 spring-cloud-stream 和绑定器依赖项以及自动配置类,有效地将您的 boot 应用程序的上下文设置为 Spring Cloud Stream 应用程序。在这种上下文中,Supplier、Function 或 Consumer 类型的 bean 被视为实际的消息处理程序,触发绑定到通过提供的绑定器公开的目标,遵循某些命名约定和规则,以避免额外的配置。
绑定和绑定名称
绑定是一种抽象,它表示绑定器和用户代码公开的源和目标之间的桥梁。此抽象有一个名称,虽然我们尽力限制运行 spring-cloud-stream 应用程序所需的配置,但在需要额外每绑定配置的情况下,了解此类名称是必要的。
在本手册中,您将看到配置属性的示例,例如 spring.cloud.stream.bindings.input.destination=myQueue。此属性名称中的 input 部分就是我们所说的绑定名称,它可以通过多种机制派生。以下小节将描述 spring-cloud-stream 用于控制绑定名称的命名约定和配置元素。
如果您的绑定名称包含特殊字符,例如 . 字符,则需要用括号 ([]) 将绑定键括起来,然后用引号括起来。例如 spring.cloud.stream.bindings."[my.output.binding.key]".destination。 |
函数式绑定名称
与 Spring Cloud Stream 早期版本中使用的基于注解(传统)的显式命名不同,函数式编程模型在绑定名称方面默认采用简单的约定,从而大大简化了应用程序配置。让我们看第一个示例
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}
在前面的示例中,我们有一个应用程序,其中包含一个作为消息处理程序的单个函数。作为一个 Function,它有一个输入和输出。用于命名输入和输出绑定的命名约定如下
-
输入 -
<functionName> + -in- + <index> -
输出 -
<functionName> + -out- + <index>
in 和 out 对应于绑定的类型(例如输入或输出)。index 是输入或输出绑定的索引。对于典型的单输入/输出函数,它始终为 0,因此仅与具有多个输入和输出参数的函数相关。
因此,例如,如果您想将此函数的输入映射到名为“my-topic”的远程目标(例如主题、队列等),您可以使用以下属性完成此操作
--spring.cloud.stream.bindings.uppercase-in-0.destination=my-topic
请注意 uppercase-in-0 如何用作属性名中的一个部分。uppercase-out-0 也是如此。
描述性绑定名称
有时为了提高可读性,您可能希望为绑定提供更具描述性的名称(例如“account”、“orders”等)。另一种看待它的方式是,您可以将隐式绑定名称映射到显式绑定名称。您可以使用 spring.cloud.stream.function.bindings.<binding-name> 属性来完成此操作。此属性还为依赖自定义基于接口的绑定(需要显式名称)的现有应用程序提供了迁移路径。
例如,
--spring.cloud.stream.function.bindings.uppercase-in-0=input
在前面的示例中,您映射并有效地将 uppercase-in-0 绑定名称重命名为 input。现在所有配置属性都可以引用 input 绑定名称(例如,--spring.cloud.stream.bindings.input.destination=my-topic)。
尽管描述性绑定名称可以增强配置的可读性方面,但它们也通过将隐式绑定名称映射到显式绑定名称而创建了另一层误导。并且由于所有后续配置属性都将使用显式绑定名称,因此您必须始终引用此“bindings”属性以关联它实际对应哪个函数。我们认为对于大多数情况(函数组合除外),这可能有些过度,因此,我们建议完全避免使用它,特别是因为不使用它可以在绑定器目标和绑定名称之间提供清晰的路径,例如 spring.cloud.stream.bindings.uppercase-in-0.destination=sample-topic,在这里您清楚地将 uppercase 函数的输入与 sample-topic 目标关联起来。 |
有关属性和其他配置选项的更多信息,请参阅 配置选项 部分。
显式绑定创建
在上一节中,我们解释了如何根据应用程序提供的 Function、Supplier 或 Consumer bean 的名称隐式创建绑定。但是,有时您可能需要显式创建绑定,其中绑定不与任何函数相关联。这通常是为了支持通过 StreamBridge 与其他框架集成而完成的。
Spring Cloud Stream 允许您通过 spring.cloud.stream.input-bindings 和 spring.cloud.stream.output-bindings 属性显式定义输入和输出绑定。请注意属性名称中的复数形式,允许您通过简单地使用 ; 作为分隔符来定义多个绑定。只需将以下测试用例作为示例
@Test
public void testExplicitBindings() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(EmptyConfiguration.class))
.web(WebApplicationType.NONE)
.run("--spring.jmx.enabled=false",
"--spring.cloud.stream.input-bindings=fooin;barin",
"--spring.cloud.stream.output-bindings=fooout;barout")) {
. . .
}
}
@EnableAutoConfiguration
@Configuration
public static class EmptyConfiguration {
}
如您所见,我们声明了两个输入绑定和两个输出绑定,而我们的配置中没有定义任何函数,但我们仍然能够成功创建这些绑定并访问其相应的通道。
生产和消费消息
您可以通过简单地编写函数并将它们作为 @Bean 公开来编写 Spring Cloud Stream 应用程序。您还可以使用基于 Spring Integration 注解的配置或基于 Spring Cloud Stream 注解的配置,尽管从 spring-cloud-stream 3.x 开始,我们建议使用函数式实现。
Spring Cloud Function 支持
概述
自 Spring Cloud Stream v2.1 以来,定义流处理程序和源的另一种替代方法是使用对 Spring Cloud Function 的内置支持,其中它们可以表示为 java.util.function.[Supplier/Function/Consumer] 类型的 bean。
要指定哪个函数式 bean 绑定到由绑定公开的外部目标,您必须提供 spring.cloud.function.definition 属性。
如果您只有一个 java.util.function.[Supplier/Function/Consumer] 类型的 bean,则可以跳过 spring.cloud.function.definition 属性,因为此类函数式 bean 将被自动发现。但是,使用此类属性以避免任何混淆被认为是最佳实践。有时,这种自动发现可能会妨碍,因为单个 java.util.function.[Supplier/Function/Consumer] 类型的 bean 可能存在用于处理消息以外的目的,但由于是单个,它会被自动发现和自动绑定。对于这些罕见的场景,您可以通过提供 spring.cloud.stream.function.autodetect 属性并将其值设置为 false 来禁用自动发现。 |
这是应用程序公开消息处理程序作为 java.util.function.Function 的示例,通过充当数据的消费者和生产者,有效地支持直通语义。
@SpringBootApplication
public class MyFunctionBootApp {
public static void main(String[] args) {
SpringApplication.run(MyFunctionBootApp.class);
}
@Bean
public Function<String, String> toUpperCase() {
return s -> s.toUpperCase();
}
}
在前面的示例中,我们定义了一个名为 toUpperCase 的 java.util.function.Function 类型的 bean,作为消息处理程序,其“input”和“output”必须绑定到由提供的目标绑定器公开的外部目标。默认情况下,“input”和“output”绑定名称将为 toUpperCase-in-0 和 toUpperCase-out-0。有关用于建立绑定名称的命名约定的详细信息,请参阅 函数式绑定名称 部分。
以下是支持其他语义的简单函数式应用程序示例
以下是公开为 java.util.function.Supplier 的源语义的示例
@SpringBootApplication
public static class SourceFromSupplier {
@Bean
public Supplier<Date> date() {
return () -> new Date(12345L);
}
}
以下是公开为 java.util.function.Consumer 的接收器语义的示例
@SpringBootApplication
public static class SinkFromConsumer {
@Bean
public Consumer<String> sink() {
return System.out::println;
}
}
供应器(Sources)
Function 和 Consumer 在其调用触发方式上非常简单。它们根据发送到它们绑定的目标的数据(事件)触发。换句话说,它们是经典的事件驱动组件。
然而,Supplier 在触发方面属于其自己的类别。由于它本质上是数据的来源(起点),因此它不订阅任何入站目标,因此必须由其他机制触发。此外,还有一个关于 Supplier 实现的问题,它可能是命令式或响应式,这直接关系到此类供应器的触发。
考虑以下示例
@SpringBootApplication
public static class SupplierConfiguration {
@Bean
public Supplier<String> stringSupplier() {
return () -> "Hello from Supplier";
}
}
每当调用其 get() 方法时,前面的 Supplier bean 都会生成一个字符串。但是,谁调用此方法,以及多久调用一次?该框架提供了一个默认的轮询机制(回答“谁?”的问题),它将触发供应商的调用,并且默认情况下每秒执行一次(回答“多久?”的问题)。换句话说,上述配置每秒生成一条消息,每条消息都会发送到由绑定器公开的 output 目标。要了解如何自定义轮询机制,请参阅 轮询配置属性 部分。
考虑一个不同的例子
@SpringBootApplication
public static class SupplierConfiguration {
@Bean
public Supplier<Flux<String>> stringSupplier() {
return () -> Flux.fromStream(Stream.generate(new Supplier<String>() {
@Override
public String get() {
try {
Thread.sleep(1000);
return "Hello from Supplier";
} catch (Exception e) {
// ignore
}
}
})).subscribeOn(Schedulers.elastic()).share();
}
}
前面的 Supplier bean 采用了响应式编程风格。通常,与命令式供应商不同,它应该只触发一次,因为调用其 get() 方法会产生(供应)连续的消息流,而不是单个消息。
该框架识别编程风格的差异,并保证此类供应商只触发一次。
然而,想象一下这样的用例:您希望轮询某个数据源并返回一个表示结果集的有限数据流。响应式编程风格是此类 Supplier 的完美机制。然而,鉴于生成流的有限性质,此类 Supplier 仍然需要定期调用。
考虑以下示例,它通过生成有限数据流来模拟此类用例
@SpringBootApplication
public static class SupplierConfiguration {
@PollableBean
public Supplier<Flux<String>> stringSupplier() {
return () -> Flux.just("hello", "bye");
}
}
bean 本身用 PollableBean 注解(@Bean 的子集)进行注解,从而向框架发出信号,表示尽管此类供应商的实现是响应式的,但它仍然需要轮询。
PollableBean 中定义了一个 splittable 属性,它向此注解的后处理器发出信号,表示由注解组件产生的结果必须拆分,并且默认设置为 true。这意味着框架将拆分返回的,将每个项作为单独的消息发送出去。如果这不是期望的行为,您可以将其设置为 false,此时此类供应商将简单地返回生成的 Flux 而不进行拆分。 |
供应器和线程
正如您现在所了解的,与由事件触发(它们有输入数据)的 Function 和 Consumer 不同,Supplier 没有任何输入,因此由不同的机制——轮询器触发,它可能具有不可预测的线程机制。虽然线程机制的细节在大多数情况下与函数的下游执行无关,但在某些情况下可能会出现问题,特别是与可能对线程亲和性有特定期望的集成框架。例如,依赖于存储在线程局部中的跟踪数据的 Spring Cloud Sleuth。对于这些情况,我们通过 StreamBridge 提供了另一种机制,用户可以更好地控制线程机制。您可以在 向输出发送任意数据(例如,外部事件驱动源) 部分获取更多详细信息。 |
消费者(Reactive)
响应式 Consumer 有点特殊,因为它具有 void 返回类型,导致框架没有可订阅的引用。您很可能不需要编写 Consumer<Flux<?>>,而是将其编写为 Function<Flux<?>, Mono<Void>>,将 then 运算符作为流上的最后一个运算符调用。
例如:
public Function<Flux<?>, Mono<Void>> consumer() {
return flux -> flux.map(..).filter(..).then();
}
但是,如果您确实需要编写显式的 Consumer<Flux<?>>,请记住订阅传入的 Flux。
此外,请记住,在混合响应式和命令式函数时,函数组合也适用相同的规则。Spring Cloud Function 确实支持将响应式函数与命令式函数组合,但是您必须注意某些限制。例如,假设您已经将响应式函数与命令式消费者组合。这种组合的结果是一个响应式 Consumer。然而,如本节前面所讨论的,没有办法订阅此类消费者,因此此限制只能通过使您的消费者响应式并手动订阅(如前所述)或将您的函数更改为命令式来解决。
轮询配置属性
Spring Cloud Stream 公开了以下属性,并以 spring.integration.poller. 为前缀
- fixedDelay
-
默认轮询器的固定延迟,单位为毫秒。
默认值:1000L。
- maxMessagesPerPoll
-
默认轮询器每次轮询事件的最大消息数。
默认值:1L。
- cron
-
Cron Trigger 的 Cron 表达式值。
默认值:无。
- initialDelay
-
周期性触发器的初始延迟。
默认值:0。
- timeUnit
-
应用于延迟值的时间单位。
默认值:MILLISECONDS。
例如 --spring.integration.poller.fixed-delay=2000 将轮询器间隔设置为每两秒轮询一次。
每绑定轮询配置
上一节展示了如何配置一个将应用于所有绑定的单个默认轮询器。虽然它非常适合微服务的模型,即每个微服务代表一个组件(例如 Supplier),因此默认轮询器配置就足够了,但存在一些特殊情况,您可能需要几个需要不同轮询配置的组件
对于这种情况,请使用每绑定方式配置轮询器。例如,假设您有一个输出绑定 supply-out-0。在这种情况下,您可以使用 spring.cloud.stream.bindings.supply-out-0.producer.poller.. 前缀来配置此类绑定的轮询器(例如,spring.cloud.stream.bindings.supply-out-0.producer.poller.fixed-delay=2000)。
向输出发送任意数据(例如,外部事件驱动源)
在某些情况下,数据的实际来源可能来自非绑定器的外部(外部)系统。例如,数据来源可能是一个经典的 REST 端点。我们如何将此类来源与 spring-cloud-stream 使用的功能机制连接起来?
Spring Cloud Stream 提供了两种机制,所以让我们更详细地了解它们
在这里,对于这两个示例,我们将使用一个名为 delegateToSupplier 的标准 MVC 端点方法,绑定到根 Web 上下文,通过 StreamBridge 机制将传入请求委托给流。
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class, "--spring.cloud.stream.output-bindings=toStream");
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("toStream", body);
}
}
这里我们自动装配一个 StreamBridge bean,它允许我们将数据发送到输出绑定,有效地将非流应用程序与 Spring Cloud Stream 连接起来。请注意,前面的示例没有定义任何源函数(例如,Supplier bean),使得框架无法提前创建源绑定,这在配置包含函数 bean 的情况下很常见。这没关系,因为 StreamBridge 将在第一次调用其 send(..) 操作时为不存在的绑定启动输出绑定的创建(以及必要的目的地自动配置),并将其缓存以供后续重用(有关详细信息,请参阅 StreamBridge 和动态目的地)。
但是,如果您想在初始化(启动)时预先创建输出绑定,您可以利用 spring.cloud.stream.output-bindings 属性来声明您的源名称。提供的名称将用作触发器来创建源绑定。您可以使用 ; 表示多个源(多个输出绑定)(例如,--spring.cloud.stream.output-bindings=foo;bar)
此外,请注意 streamBridge.send(..) 方法接受 Object 作为数据。这意味着您可以向其发送 POJO 或 Message,并且它在发送输出时将经历与任何 Function 或 Supplier 相同的例程,提供与函数相同的一致性级别。这意味着输出类型转换、分区等将像函数产生的输出一样得到遵守。
StreamBridge 和动态目的地
StreamBridge 也可以用于提前不知道输出目的地的情况,类似于 从消费者路由 部分中描述的用例。
让我们来看一个例子
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class, args);
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("myDestination", body);
}
}
如您所见,前面的示例与前一个非常相似,只是没有通过 spring.cloud.stream.output-bindings 属性提供显式绑定指令。在这里,我们将数据发送到 myDestination 名称,该名称不存在作为绑定。因此,此类名称将被视为动态目的地,如 从消费者路由 部分所述。
在前面的示例中,我们使用 ApplicationRunner 作为外部源来为流提供数据。
一个更实际的例子,其中外部源是 REST 端点。
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class);
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
streamBridge.send("myBinding", body);
}
}
如您所见,在 delegateToSupplier 方法内部,我们使用 StreamBridge 将数据发送到 myBinding 绑定。在这里,您也受益于 StreamBridge 的动态功能,如果 myBinding 不存在,它将自动创建并缓存,否则将使用现有绑定。
缓存动态目的地(绑定)可能会导致内存泄漏,如果动态目的地很多。为了在一定程度上进行控制,我们为输出绑定提供了自清除缓存机制,默认缓存大小为 10。这意味着如果您的动态目的地大小超过该数字,则可能会逐出现有绑定,从而需要重新创建,这可能会导致轻微的性能下降。您可以通过 spring.cloud.stream.dynamic-destination-cache-size 属性将其设置为所需值来增加缓存大小。 |
curl -H "Content-Type: text/plain" -X POST -d "hello from the other side" https://:8080/
通过展示两个示例,我们强调该方法适用于任何类型的外部源。
如果您正在使用 Solace PubSub+ 绑定器,Spring Cloud Stream 已保留了 scst_targetDestination 标头(可通过 BinderHeaders.TARGET_DESTINATION 获取),该标头允许消息从其绑定配置的目的地重定向到此标头指定的目标目的地。这允许绑定器管理发布到动态目的地所需的资源,从而减轻了框架的负担,并避免了前面注意事项中提到的缓存问题。更多信息请参见此处。 |
StreamBridge 的输出内容类型
您还可以通过以下方法签名 public boolean send(String bindingName, Object data, MimeType outputContentType) 提供特定的内容类型。或者,如果您将数据作为 Message 发送,则其内容类型将得到遵守。
使用 StreamBridge 的特定绑定器类型
Spring Cloud Stream 支持多种绑定器场景。例如,您可能正在从 Kafka 接收数据并将其发送到 RabbitMQ。
如果您打算使用 StreamBridge 并且您的应用程序中配置了多个绑定器,您还必须告诉 StreamBridge 使用哪个绑定器。为此,send 方法还有另外两种变体
public boolean send(String bindingName, @Nullable String binderType, Object data)
public boolean send(String bindingName, @Nullable String binderType, Object data, MimeType outputContentType)
如您所见,您可以提供一个额外的参数 - binderType,告诉 BindingService 在创建动态绑定时使用哪个绑定器。
对于使用 spring.cloud.stream.output-bindings 属性或绑定已在不同绑定器下创建的情况,binderType 参数将不起作用。 |
使用 StreamBridge 的通道拦截器
由于 StreamBridge 使用 MessageChannel 建立输出绑定,因此在通过 StreamBridge 发送数据时可以激活通道拦截器。由应用程序决定将哪些通道拦截器应用于 StreamBridge。Spring Cloud Stream 不会将检测到的所有通道拦截器注入到 StreamBridge 中,除非它们用 @GlobalChannelInterceptor(patterns = "*") 进行注解。
让我们假设您的应用程序中有以下两个不同的 StreamBridge 绑定。
streamBridge.send("foo-out-0", message);
和
streamBridge.send("bar-out-0", message);
现在,如果您想在两个 StreamBridge 绑定上都应用通道拦截器,那么您可以声明以下 GlobalChannelInterceptor bean。
@Bean
@GlobalChannelInterceptor(patterns = "*")
public ChannelInterceptor customInterceptor() {
return new ChannelInterceptor() {
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
...
}
};
}然而,如果您不喜欢上述全局方法,并且希望为每个绑定提供专用拦截器,那么您可以执行以下操作。
@Bean
@GlobalChannelInterceptor(patterns = "foo-*")
public ChannelInterceptor fooInterceptor() {
return new ChannelInterceptor() {
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
...
}
};
}和
@Bean
@GlobalChannelInterceptor(patterns = "bar-*")
public ChannelInterceptor barInterceptor() {
return new ChannelInterceptor() {
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
...
}
};
}您可以灵活地使模式更严格或根据您的业务需求进行定制。
通过这种方法,应用程序能够决定将哪些拦截器注入到 StreamBridge 中,而不是应用所有可用的拦截器。
StreamBridge 通过 StreamOperations 接口提供了一个契约,该接口包含 StreamBridge 的所有 send 方法。因此,应用程序可以选择使用 StreamOperations 进行自动装配。这在通过为 StreamOperations 接口提供模拟或类似机制来对使用 StreamBridge 的代码进行单元测试时非常方便。 |
响应式函数支持
由于 Spring Cloud Function 是构建在 Project Reactor 之上的,因此在实现 Supplier、Function 或 Consumer 时,您无需做太多即可受益于响应式编程模型。
例如:
@SpringBootApplication
public static class SinkFromConsumer {
@Bean
public Function<Flux<String>, Flux<String>> reactiveUpperCase() {
return flux -> flux.map(val -> val.toUpperCase());
}
}
|
在选择响应式或命令式编程模型时,必须理解几个重要事项。 完全响应式还是仅 API? 使用响应式 API 不一定意味着您可以受益于此类 API 的所有响应式功能。换句话说,像背压和其他高级功能只有在与兼容系统(例如 Reactive Kafka 绑定器)一起使用时才能工作。如果您使用常规 Kafka 或 Rabbit 或任何其他非响应式绑定器,您只能从响应式 API 本身的便利性中受益,而不是其高级功能,因为流的实际源或目标不是响应式的。 错误处理和重试 在本手册中,您将看到一些关于基于框架的错误处理、重试和其他功能以及与其相关的配置属性的引用。重要的是要理解它们只影响命令式函数,并且您不应期望响应式函数具有相同的行为。原因如下:响应式函数与命令式函数之间存在根本区别。命令式函数是一个消息处理程序,它由框架在接收到每条消息时调用。因此,对于 N 条消息,将有 N 次此类函数的调用,正因为如此,我们可以封装此类函数并添加额外的功能,例如错误处理、重试等。响应式函数是初始化函数。它只调用一次,以获取用户提供的 Flux/Mono 的引用,以便与框架提供的 Flux/Mono 连接。之后,我们(框架)对流完全没有可见性或控制。因此,对于响应式函数,您必须依靠响应式 API 的丰富性来进行错误处理和重试(即 |
函数组合
使用函数式编程模型,您还可以受益于函数式组合,通过它您可以从一组简单函数动态组合复杂的处理程序。举例来说,让我们将以下函数 bean 添加到上面定义的应用程序中
@Bean
public Function<String, String> wrapInQuotes() {
return s -> "\"" + s + "\"";
}
并修改 spring.cloud.function.definition 属性以反映您组合新函数(由“toUpperCase”和“wrapInQuotes”组成)的意图。为此,Spring Cloud Function 依赖于 |(管道)符号。因此,为了完成我们的示例,我们的属性现在将如下所示
--spring.cloud.function.definition=toUpperCase|wrapInQuotes
| Spring Cloud Function 提供的函数组合支持的最大好处之一是您可以组合响应式和命令式函数。 |
组合的结果是一个单一函数,正如你可能猜到的那样,它可能有一个很长且相当神秘的名称(例如,foo|bar|baz|xyz. . .),这在处理其他配置属性时会带来很大的不便。这就是 函数式绑定名称 部分中描述的描述性绑定名称功能可以提供帮助的地方。
例如,如果我们想给 toUpperCase|wrapInQuotes 一个更具描述性的名称,我们可以使用以下属性 spring.cloud.stream.function.bindings.toUpperCase|wrapInQuotes-in-0=quotedUpperCaseInput 来实现,允许其他配置属性引用该绑定名称(例如,spring.cloud.stream.bindings.quotedUpperCaseInput.destination=myDestination)。
函数组合与横切关注点
函数组合有效地允许您通过将其分解为一组简单且可单独管理/测试的组件来解决复杂性,这些组件在运行时仍然可以表示为一个。但这并非唯一的好处。
您还可以使用组合来处理某些横切非功能性关注点,例如内容丰富。例如,假设您有一个传入消息可能缺少某些标头,或者某些标头不符合您的业务函数期望的精确状态。您现在可以实现一个单独的函数来解决这些关注点,然后将其与主要业务函数组合起来。
让我们来看一个例子
@SpringBootApplication
public class DemoStreamApplication {
public static void main(String[] args) {
SpringApplication.run(DemoStreamApplication.class,
"--spring.cloud.function.definition=enrich|echo",
"--spring.cloud.stream.function.bindings.enrich|echo-in-0=input",
"--spring.cloud.stream.bindings.input.destination=myDestination",
"--spring.cloud.stream.bindings.input.group=myGroup");
}
@Bean
public Function<Message<String>, Message<String>> enrich() {
return message -> {
Assert.isTrue(!message.getHeaders().containsKey("foo"), "Should NOT contain 'foo' header");
return MessageBuilder.fromMessage(message).setHeader("foo", "bar").build();
};
}
@Bean
public Function<Message<String>, Message<String>> echo() {
return message -> {
Assert.isTrue(message.getHeaders().containsKey("foo"), "Should contain 'foo' header");
System.out.println("Incoming message " + message);
return message;
};
}
}
虽然微不足道,但此示例演示了一个函数如何通过附加标头(非功能性关注点)丰富传入消息,以便另一个函数(echo)可以从中受益。echo 函数保持简洁,只关注业务逻辑。您还可以看到 spring.cloud.stream.function.bindings 属性的使用,以简化组合绑定名称。
具有多个输入和输出参数的函数
从 3.0 版本开始,spring-cloud-stream 支持具有多个输入和/或多个输出(返回值)的函数。这到底意味着什么,它针对哪些用例?
-
大数据:想象您正在处理的数据源是高度无组织的,包含各种类型的数据元素(例如订单、事务等),并且您需要有效地对其进行排序。
-
数据聚合:另一个用例可能需要您合并来自 2 个或更多传入_流_的数据元素.
上述只是描述了您可能需要使用单个函数来接受和/或生成多个数据流的一些用例。这正是我们在此处关注的用例类型。
此外,请注意此处对流概念的略微不同强调。假设这些函数只有在它们被赋予访问实际数据流(而不是单个元素)的权限时才有价值。为此,我们依赖于 Project Reactor 提供的抽象(即 Flux 和 Mono),这些抽象作为 spring-cloud-functions 引入的依赖项的一部分已在类路径上可用。
另一个重要的方面是多个输入和输出的表示。虽然 Java 提供了各种不同的抽象来表示多个事物,但这些抽象是 a) 无界的、b) 缺乏元数 和 c) 缺乏类型信息,这些在上下文中都很重要。举例来说,让我们看看 Collection 或数组,它们只允许我们描述单个类型的多个,或者将所有内容向上转换为 Object,从而影响 spring-cloud-stream 的透明类型转换功能等等。
因此,为了满足所有这些要求,最初的支持依赖于使用 Project Reactor 提供的另一个抽象——元组的签名。但是,我们正在努力允许更灵活的签名。
| 请参阅 绑定和绑定名称 部分,以了解此类应用程序使用的建立绑定名称的命名约定。 |
让我们看几个示例
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<Tuple2<Flux<String>, Flux<Integer>>, Flux<String>> gather() {
return tuple -> {
Flux<String> stringStream = tuple.getT1();
Flux<String> intStream = tuple.getT2().map(i -> String.valueOf(i));
return Flux.merge(stringStream, intStream);
};
}
}
上述示例演示了一个函数,它接受两个输入(第一个是 String 类型,第二个是 Integer 类型),并生成一个 String 类型的输出。
因此,对于上述示例,两个输入绑定将是 gather-in-0 和 gather-in-1,为了保持一致性,输出绑定也遵循相同的约定,并命名为 gather-out-0。
了解这些将允许您设置绑定特定的属性。例如,以下内容将覆盖gather-in-0绑定的内容类型
--spring.cloud.stream.bindings.gather-in-0.content-type=text/plain
@SpringBootApplication
public class SampleApplication {
@Bean
public static Function<Flux<Integer>, Tuple2<Flux<String>, Flux<String>>> scatter() {
return flux -> {
Flux<Integer> connectedFlux = flux.publish().autoConnect(2);
UnicastProcessor even = UnicastProcessor.create();
UnicastProcessor odd = UnicastProcessor.create();
Flux<Integer> evenFlux = connectedFlux.filter(number -> number % 2 == 0).doOnNext(number -> even.onNext("EVEN: " + number));
Flux<Integer> oddFlux = connectedFlux.filter(number -> number % 2 != 0).doOnNext(number -> odd.onNext("ODD: " + number));
return Tuples.of(Flux.from(even).doOnSubscribe(x -> evenFlux.subscribe()), Flux.from(odd).doOnSubscribe(x -> oddFlux.subscribe()));
};
}
}
上述示例与前一个示例有些相反,它演示了一个函数,该函数接收一个Integer类型的输入,并产生两个输出(都为String类型)。
因此,对于上述示例,输入绑定是scatter-in-0,输出绑定是scatter-out-0和scatter-out-1。
您可以使用以下代码进行测试
@Test
public void testSingleInputMultiOutput() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleApplication.class))
.run("--spring.cloud.function.definition=scatter")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
for (int i = 0; i < 10; i++) {
inputDestination.send(MessageBuilder.withPayload(String.valueOf(i).getBytes()).build());
}
int counter = 0;
for (int i = 0; i < 5; i++) {
Message<byte[]> even = outputDestination.receive(0, 0);
assertThat(even.getPayload()).isEqualTo(("EVEN: " + String.valueOf(counter++)).getBytes());
Message<byte[]> odd = outputDestination.receive(0, 1);
assertThat(odd.getPayload()).isEqualTo(("ODD: " + String.valueOf(counter++)).getBytes());
}
}
}
单个应用程序中的多个函数
可能还需要在单个应用程序中对多个消息处理程序进行分组。您可以通过定义多个函数来实现。
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
@Bean
public Function<String, String> reverse() {
return value -> new StringBuilder(value).reverse().toString();
}
}
在上述示例中,我们有一个定义了两个函数uppercase和reverse的配置。因此,首先,如前所述,我们需要注意到存在冲突(多于一个函数),因此我们需要通过提供指向我们想要绑定的实际函数的spring.cloud.function.definition属性来解决它。但是在这里,我们将使用;分隔符来指向这两个函数(参见下面的测试用例)。
| 与具有多个输入/输出的函数一样,请参阅绑定和绑定名称部分,以了解此类应用程序使用的绑定名称的命名约定。 |
您可以使用以下代码进行测试
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
ReactiveFunctionConfiguration.class))
.run("--spring.cloud.function.definition=uppercase;reverse")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "uppercase-in-0");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "uppercase-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-1");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}
批量消费者
当使用支持批量侦听器且为消费者绑定启用了该功能的MessageChannelBinder时,您可以将spring.cloud.stream.bindings.<binding-name>.consumer.batch-mode设置为true,以将整个消息批次以List形式传递给函数。
@Bean
public Function<List<Person>, Person> findFirstPerson() {
return persons -> persons.get(0);
}
批量生产者
您也可以在生产者端使用批处理的概念,通过返回一个消息集合,这实际上提供了相反的效果,即集合中的每条消息都将由绑定器单独发送。
考虑以下函数
@Bean
public Function<String, List<Message<String>>> batch() {
return p -> {
List<Message<String>> list = new ArrayList<>();
list.add(MessageBuilder.withPayload(p + ":1").build());
list.add(MessageBuilder.withPayload(p + ":2").build());
list.add(MessageBuilder.withPayload(p + ":3").build());
list.add(MessageBuilder.withPayload(p + ":4").build());
return list;
};
}
返回列表中的每条消息都将单独发送,导致四条消息发送到输出目的地。
Spring Integration 流作为函数
当您实现一个函数时,您可能有一些复杂的请求,这些请求符合企业集成模式(EIP)的类别。这些请求最好通过使用像Spring Integration(SI)这样的框架来处理,它是EIP的参考实现。
幸运的是,SI 已经通过 集成流作为网关 提供了将集成流作为函数公开的支持。考虑以下示例
@SpringBootApplication
public class FunctionSampleSpringIntegrationApplication {
public static void main(String[] args) {
SpringApplication.run(FunctionSampleSpringIntegrationApplication.class, args);
}
@Bean
public IntegrationFlow uppercaseFlow() {
return IntegrationFlows.from(MessageFunction.class, "uppercase")
.<String, String>transform(String::toUpperCase)
.logAndReply(LoggingHandler.Level.WARN);
}
public interface MessageFunction extends Function<Message<String>, Message<String>> {
}
}
对于熟悉 SI 的人来说,您可以看到我们定义了一个 IntegrationFlow 类型的 bean,其中我们声明了一个要公开为 Function<String, String>(使用 SI DSL)的集成流,名为 uppercase。MessageFunction 接口允许我们明确声明输入和输出的类型,以进行正确的类型转换。有关类型转换的更多信息,请参阅内容类型协商部分。
要接收原始输入,您可以使用from(Function.class, …)。
生成的函数绑定到目标绑定器公开的输入和输出目的地。
| 请参阅 绑定和绑定名称 部分,以了解此类应用程序使用的建立绑定名称的命名约定。 |
有关 Spring Integration 和 Spring Cloud Stream 之间互操作性的更多详细信息,特别是关于函数式编程模型,您可能会发现这篇文章非常有趣,因为它更深入地探讨了通过融合 Spring Integration 和 Spring Cloud Stream/Functions 的优点可以应用的各种模式。
使用轮询消费者
概述
当使用轮询消费者时,您按需轮询PollableMessageSource。要为轮询消费者定义绑定,您需要提供spring.cloud.stream.pollable-source属性。
考虑以下轮询消费者绑定的示例
--spring.cloud.stream.pollable-source=myDestination在前面的例子中,轮询源名称myDestination将导致myDestination-in-0绑定名称,以与函数式编程模型保持一致。
鉴于前面示例中的轮询消费者,您可能会按如下方式使用它
@Bean
public ApplicationRunner poller(PollableMessageSource destIn, MessageChannel destOut) {
return args -> {
while (someCondition()) {
try {
if (!destIn.poll(m -> {
String newPayload = ((String) m.getPayload()).toUpperCase();
destOut.send(new GenericMessage<>(newPayload));
})) {
Thread.sleep(1000);
}
}
catch (Exception e) {
// handle failure
}
}
};
}
一种更少手动且更像 Spring 的替代方案是配置一个调度任务 bean。例如,
@Scheduled(fixedDelay = 5_000)
public void poll() {
System.out.println("Polling...");
this.source.poll(m -> {
System.out.println(m.getPayload());
}, new ParameterizedTypeReference<Foo>() { });
}
PollableMessageSource.poll()方法接受一个MessageHandler参数(通常是lambda表达式,如这里所示)。如果消息被接收并成功处理,它返回true。
与消息驱动的消费者一样,如果MessageHandler抛出异常,消息将发布到错误通道,如错误处理中所述。
通常,poll()方法在MessageHandler退出时确认消息。如果该方法异常退出,消息将被拒绝(不重新排队),但请参阅处理错误。您可以通过负责确认来覆盖该行为,如以下示例所示
@Bean
public ApplicationRunner poller(PollableMessageSource dest1In, MessageChannel dest2Out) {
return args -> {
while (someCondition()) {
if (!dest1In.poll(m -> {
StaticMessageHeaderAccessor.getAcknowledgmentCallback(m).noAutoAck();
// e.g. hand off to another thread which can perform the ack
// or acknowledge(Status.REQUEUE)
})) {
Thread.sleep(1000);
}
}
};
}
您必须在某个时刻ack(或nack)消息,以避免资源泄漏。 |
一些消息系统(例如 Apache Kafka)维护一个简单的日志偏移量。如果交付失败并使用StaticMessageHeaderAccessor.getAcknowledgmentCallback(m).acknowledge(Status.REQUEUE);重新排队,任何后续成功确认的消息都将被重新交付。 |
还有一个重载的poll方法,其定义如下
poll(MessageHandler handler, ParameterizedTypeReference<?> type)
type是一个转换提示,允许对传入消息的有效负载进行转换,如下例所示
boolean result = pollableSource.poll(received -> {
Map<String, Foo> payload = (Map<String, Foo>) received.getPayload();
...
}, new ParameterizedTypeReference<Map<String, Foo>>() {});
处理错误
默认情况下,轮询源配置了一个错误通道;如果回调抛出异常,一个ErrorMessage将被发送到错误通道(<destination>.<group>.errors);此错误通道也桥接到全局 Spring Integration errorChannel。
您可以使用@ServiceActivator订阅任何一个错误通道来处理错误;如果没有订阅,错误将简单地记录下来,消息将被确认为成功。如果错误通道服务激活器抛出异常,消息将被拒绝(默认情况下)并且不会重新发送。如果服务激活器抛出RequeueCurrentMessageException,消息将在代理处重新排队,并在后续的轮询中再次检索。
如果监听器直接抛出RequeueCurrentMessageException,消息将被重新排队,如上所述,并且不会发送到错误通道。
事件路由
在 Spring Cloud Stream 的上下文中,事件路由是指a) 将事件路由到特定的事件订阅者或b) 将事件订阅者生成的事件路由到特定的目的地的能力。这里我们将其称为“路由到”和“路由来自”。
路由到消费者
通过依赖 Spring Cloud Function 3.0 中提供的 RoutingFunction 可以实现路由。您所需要做的就是通过 --spring.cloud.stream.function.routing.enabled=true 应用程序属性启用它,或者提供 spring.cloud.function.routing-expression 属性。一旦启用,RoutingFunction 将绑定到输入目的地,接收所有消息并根据提供的指令将它们路由到其他函数。
为了绑定的目的,路由目的地的名称是functionRouter-in-0(参见RoutingFunction.FUNCTION_NAME和绑定命名约定函数绑定名称)。 |
指令可以通过单独的消息和应用程序属性提供。
这里有几个例子
使用消息头
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class,
"--spring.cloud.stream.function.routing.enabled=true");
}
@Bean
public Consumer<String> even() {
return value -> {
System.out.println("EVEN: " + value);
};
}
@Bean
public Consumer<String> odd() {
return value -> {
System.out.println("ODD: " + value);
};
}
}
通过向绑定器公开的functionRouter-in-0目的地(即 rabbit, kafka)发送消息,该消息将被路由到适当的(“even”或“odd”)消费者。
默认情况下,RoutingFunction将查找spring.cloud.function.definition或spring.cloud.function.routing-expression(对于具有 SpEL 的更动态场景)头部,如果找到,其值将被视为路由指令。
例如,将spring.cloud.function.routing-expression头设置为值T(java.lang.System).currentTimeMillis() % 2 == 0 ? 'even' : 'odd'将最终半随机地将请求路由到odd或even函数。此外,对于 SpEL,评估上下文的根对象是Message,因此您也可以对单个头(或消息)进行评估,例如….routing-expression=headers['type']
使用应用程序属性
spring.cloud.function.routing-expression和/或spring.cloud.function.definition可以作为应用程序属性传递(例如,spring.cloud.function.routing-expression=headers['type'])。
@SpringBootApplication
public class RoutingStreamApplication {
public static void main(String[] args) {
SpringApplication.run(RoutingStreamApplication.class,
"--spring.cloud.function.routing-expression="
+ "T(java.lang.System).nanoTime() % 2 == 0 ? 'even' : 'odd'");
}
@Bean
public Consumer<Integer> even() {
return value -> System.out.println("EVEN: " + value);
}
@Bean
public Consumer<Integer> odd() {
return value -> System.out.println("ODD: " + value);
}
}
| 通过应用程序属性传递指令对于响应式函数尤其重要,因为响应式函数只调用一次以传递Publisher,因此对单个项目的访问受到限制。 |
路由函数和输出绑定
RoutingFunction是一个Function,因此与其他任何函数都没有什么不同。嗯…几乎没有。
当RoutingFunction路由到另一个Function时,其输出将按预期发送到RoutingFunction的输出绑定,即functionRouter-in-0。但是如果RoutingFunction路由到Consumer呢?换句话说,调用RoutingFunction的结果可能不会产生任何内容发送到输出绑定,因此甚至可能不需要输出绑定。因此,我们在创建绑定时对待RoutingFunction有点不同。尽管作为用户您是透明的(您实际上什么都不需要做),但了解一些机制将有助于您理解其内部工作原理。
所以,规则是:我们从不为RoutingFunction创建输出绑定,只创建输入绑定。因此,当您路由到Consumer时,RoutingFunction通过没有输出绑定而有效地成为一个Consumer。但是,如果RoutingFunction碰巧路由到另一个生成输出的Function,则会动态创建RoutingFunction的输出绑定,此时RoutingFunction将像常规Function一样,拥有输入和输出绑定。
路由来自消费者
除了静态目的地,Spring Cloud Stream 还允许应用程序将消息发送到动态绑定的目的地。这在例如需要在运行时确定目标目的地时非常有用。应用程序可以通过两种方式实现这一点。
spring.cloud.stream.sendto.destination
您还可以通过指定spring.cloud.stream.sendto.destination头并将其设置为要解析的目标名称,将解析输出目标的任务委托给框架。
考虑以下示例
@SpringBootApplication
@Controller
public class SourceWithDynamicDestination {
@Bean
public Function<String, Message<String>> destinationAsPayload() {
return value -> {
return MessageBuilder.withPayload(value)
.setHeader("spring.cloud.stream.sendto.destination", value).build();};
}
}
尽管微不足道,您在此示例中可以清楚地看到,我们的输出是一个消息,其spring.cloud.stream.sendto.destination头设置为输入参数的值。框架将查询此头,并尝试创建或发现具有该名称的目标并向其发送输出。
如果目标名称是事先已知的,您可以像配置任何其他目标一样配置生产者属性。或者,如果您注册一个NewDestinationBindingCallback<> bean,它会在绑定创建之前被调用。回调接受绑定器使用的扩展生产者属性的通用类型。它有一个方法
void configure(String destinationName, MessageChannel channel, ProducerProperties producerProperties,
T extendedProducerProperties);
以下示例展示了如何使用 RabbitMQ 绑定器
@Bean
public NewDestinationBindingCallback<RabbitProducerProperties> dynamicConfigurer() {
return (name, channel, props, extended) -> {
props.setRequiredGroups("bindThisQueue");
extended.setQueueNameGroupOnly(true);
extended.setAutoBindDlq(true);
extended.setDeadLetterQueueName("myDLQ");
};
}
如果需要支持多种绑定器类型的动态目标,请使用Object作为泛型类型,并根据需要转换extended参数。 |
另外,请参阅[使用 StreamBridge]部分,了解StreamBridge如何用于类似情况的另一个选项。
消息发送后的后处理
函数被调用后,其结果由框架发送到目标目的地,这有效地完成了函数调用周期。
然而,从业务角度来看,在完成此周期**之后**执行一些额外任务之前,此类周期可能不完全完成。虽然这可以通过简单的Consumer和StreamBridge组合来实现,如Stack Overflow 帖子中所述,但自 4.0.3 版本以来,该框架提供了一种更惯用的方法来解决此问题,即通过 Spring Cloud Function 项目提供的PostProcessingFunction。PostProcessingFunction是一个特殊的半标记函数,它包含一个附加方法postProcess(Message>),旨在为实现此类后处理任务提供一个位置。
package org.springframework.cloud.function.context
. . .
public interface PostProcessingFunction<I, O> extends Function<I, O> {
default void postProcess(Message<O> result) {
}
}
所以,现在你有两个选择。
选项 1:您可以将您的函数实现为 PostProcessingFunction,并通过实现其 postProcess(Message>) 方法来包含额外的后处理行为。
private static class Uppercase implements PostProcessingFunction<String, String> {
@Override
public String apply(String input) {
return input.toUpperCase();
}
@Override
public void postProcess(Message<String> result) {
System.out.println("Function Uppercase has been successfully invoked and its result successfully sent to target destination");
}
}
. . .
@Bean
public Function<String, String> uppercase() {
return new Uppercase();
}
选项 2:如果您已经有一个现有函数,并且不想更改其实现,或者希望将您的函数保留为 POJO,您只需实现 postProcess(Message>) 方法,并将此新的后处理函数与您的其他函数组合。
private static class Logger implements PostProcessingFunction<?, String> {
@Override
public void postProcess(Message<String> result) {
System.out.println("Function has been successfully invoked and its result successfully sent to target destination");
}
}
. . .
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
@Bean
public Function<String, String> logger() {
return new Logger();
}
. . .
// and then have your function definition as such `uppercase|logger`
注意:在函数组合的情况下,只有最后一个PostProcessingFunction实例(如果存在)会生效。例如,假设您有以下函数定义 - foo|bar|baz,并且foo和baz都是PostProcessingFunction的实例。只有baz.postProcess(Message>)会被调用。如果baz不是PostProcessingFunction的实例,则不会执行任何后处理功能。
有人可能会争辩说,您可以通过函数组合轻松实现这一点,只需将后处理器组合成另一个Function即可。这确实是一种可能性,但在这种情况下,后处理功能将在上一个函数调用之后立即调用,并且在消息发送到目标目的地之前,即在函数调用周期完成之前。
错误处理
在本节中,我们将解释框架提供的错误处理机制背后的总体思想。我们将以 Rabbit 绑定器为例,因为各个绑定器为某些支持的机制定义了不同的属性集,这些机制特定于底层代理功能(例如 Kafka 绑定器)。
错误总会发生,Spring Cloud Stream 提供了几种灵活的机制来处理它们。请注意,这些技术取决于绑定器实现、底层消息中间件的能力以及编程模型(稍后会详细介绍)。
当消息处理程序(函数)抛出异常时,它会传播回绑定器,此时绑定器会使用Spring Retry库提供的RetryTemplate多次尝试重试相同的消息(默认3次)。如果重试不成功,则由错误处理机制决定是丢弃消息、重新排队消息进行重新处理还是将失败消息发送到DLQ。
Rabbit 和 Kafka 都支持这些概念(尤其是 DLQ)。但是,其他绑定器可能不支持,因此请参阅您的单个绑定器的文档,了解受支持的错误处理选项的详细信息。
但请记住,响应式函数不符合消息处理程序的条件,因为它不处理单个消息,而是提供一种将框架提供的流(即 Flux)与用户提供的流连接起来的方式。为什么这很重要?那是因为您在本节后面阅读的关于重试模板、丢弃失败消息、重试、DLQ 以及协助所有这些的配置属性**只**适用于消息处理程序(即命令式函数)。
响应式 API 提供了非常丰富的自身运算符和机制库,可帮助您处理特定于各种响应式用例的错误,这些用例比简单的消息处理程序用例复杂得多。因此,请使用它们,例如您可以在 reactor.core.publisher.Flux 中找到的 public final Flux<T> retryWhen(Retry retrySpec);。
@Bean
public Function<Flux<String>, Flux<String>> uppercase() {
return flux -> flux
.retryWhen(Retry.backoff(3, Duration.ofMillis(1000)))
.map(v -> v.toUpperCase());
}
丢弃失败消息
默认情况下,系统提供了错误处理程序。第一个错误处理程序将简单地记录错误消息。第二个错误处理程序是绑定器特定的错误处理程序,它负责在特定消息系统(例如,发送到 DLQ)的上下文中处理错误消息。但是由于未提供额外的错误处理配置(在此当前场景中),此处理程序将不执行任何操作。因此,在记录之后,消息将被丢弃。
虽然在某些情况下可以接受,但对于大多数情况来说,这是不可接受的,我们需要某种恢复机制来避免消息丢失。
处理错误消息
在上一节中,我们提到默认情况下,导致错误的消息会有效地记录并丢弃。框架还为您提供了提供自定义错误处理程序的机制(即发送通知或写入数据库等)。您可以通过添加专门设计用于接受ErrorMessage的Consumer来实现,该ErrorMessage除了包含有关错误的所有信息(例如,堆栈跟踪等)之外,还包含原始消息(触发错误的消息)。注意:自定义错误处理程序与框架提供的错误处理程序(即日志记录和绑定器错误处理程序 - 请参阅上一节)互斥,以确保它们不会相互干扰。
@Bean
public Consumer<ErrorMessage> myErrorHandler() {
return v -> {
// send SMS notification code
};
}
要将此类消费者标识为错误处理程序,您只需提供error-handler-definition属性,指向函数名称 - spring.cloud.stream.bindings.<binding-name>.error-handler-definition=myErrorHandler。
例如,对于绑定名称uppercase-in-0,该属性将如下所示
spring.cloud.stream.bindings.uppercase-in-0.error-handler-definition=myErrorHandler如果您使用特殊映射指令将绑定映射到更具可读性的名称 - spring.cloud.stream.function.bindings.uppercase-in-0=upper,那么此属性将如下所示
spring.cloud.stream.bindings.upper.error-handler-definition=myErrorHandler.如果您不小心将此类处理程序声明为Function,它仍然会工作,只是其输出不会做任何事情。但是,鉴于此类处理程序仍然依赖于 Spring Cloud Function 提供的功能,您也可以在处理程序具有一些复杂性时从函数组合中受益,您希望通过函数组合来解决这些复杂性(尽管不太可能)。 |
默认错误处理程序
如果您希望为所有函数 bean 使用单个错误处理程序,可以使用 Spring Cloud Stream 的标准机制来定义默认属性 spring.cloud.stream.default.error-handler-definition=myErrorHandler
DLQ - 死信队列
DLQ 可能是最常见的机制,它允许失败的消息发送到一个特殊目的地:死信队列。
配置后,失败的消息将被发送到此目的地,以进行后续的重新处理、审计和对账。
考虑以下示例
@SpringBootApplication
public class SimpleStreamApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(SimpleStreamApplication.class,
"--spring.cloud.function.definition=uppercase",
"--spring.cloud.stream.bindings.uppercase-in-0.destination=uppercase",
"--spring.cloud.stream.bindings.uppercase-in-0.group=myGroup",
"--spring.cloud.stream.rabbit.bindings.uppercase-in-0.consumer.auto-bind-dlq=true"
);
}
@Bean
public Function<Person, Person> uppercase() {
return personIn -> {
throw new RuntimeException("intentional");
});
};
}
}
提醒一下,在此示例中,属性的uppercase-in-0段对应于输入目标绑定的名称。consumer段表示它是一个消费者属性。
当使用 DLQ 时,至少必须提供 group 属性才能正确命名 DLQ 目的地。但是,group 通常与 destination 属性一起使用,如我们的示例所示。 |
除了一些标准属性,我们还将auto-bind-dlq设置为指示绑定器为uppercase-in-0绑定(对应于uppercase目的地,参见相应属性)创建和配置DLQ目的地,这将导致一个名为uppercase.myGroup.dlq的附加Rabbit队列(有关Kafka特定的DLQ属性,请参阅Kafka文档)。
配置完成后,所有失败的消息都将路由到此目的地,并保留原始消息以供后续操作。
您可以看到错误消息包含更多与原始错误相关的信息,如下所示
. . . .
x-exception-stacktrace: org.springframework.messaging.MessageHandlingException: nested exception is
org.springframework.messaging.MessagingException: has an error, failedMessage=GenericMessage [payload=byte[15],
headers={amqp_receivedDeliveryMode=NON_PERSISTENT, amqp_receivedRoutingKey=input.hello, amqp_deliveryTag=1,
deliveryAttempt=3, amqp_consumerQueue=input.hello, amqp_redelivered=false, id=a15231e6-3f80-677b-5ad7-d4b1e61e486e,
amqp_consumerTag=amq.ctag-skBFapilvtZhDsn0k3ZmQg, contentType=application/json, timestamp=1522327846136}]
at org.spring...integ...han...MethodInvokingMessageProcessor.processMessage(MethodInvokingMessageProcessor.java:107)
at. . . . .
Payload: blah您还可以通过将max-attempts设置为'1'来促进立即调度到DLQ(无需重试)。例如,
--spring.cloud.stream.bindings.uppercase-in-0.consumer.max-attempts=1重试模板
在本节中,我们将介绍与重试功能配置相关的配置属性。
RetryTemplate是Spring Retry库的一部分。虽然本文档超出范围,无法涵盖RetryTemplate的所有功能,但我们将提及以下与RetryTemplate专门相关的消费者属性
- maxAttempts
-
处理消息的尝试次数。
默认值:3。
- backOffInitialInterval
-
重试时的回退初始间隔。
默认 1000 毫秒。
- backOffMaxInterval
-
最大回退间隔。
默认 10000 毫秒。
- backOffMultiplier
-
回退乘数。
默认 2.0。
- defaultRetryable
-
侦听器抛出的未列在
retryableExceptions中的异常是否可重试。默认值:
true。 - retryableExceptions
-
一个映射,键是 Throwable 类名,值是布尔值。指定那些将或不会重试的异常(及其子类)。另请参见
defaultRetriable。示例:spring.cloud.stream.bindings.input.consumer.retryable-exceptions.java.lang.IllegalStateException=false。默认值:空。
尽管上述设置足以满足大多数定制需求,但它们可能无法满足某些复杂需求,此时您可能希望提供自己的RetryTemplate实例。为此,请在您的应用程序配置中将其配置为bean。应用程序提供的实例将覆盖框架提供的实例。此外,为了避免冲突,您必须将要由绑定器使用的RetryTemplate实例限定为@StreamRetryTemplate。例如,
@StreamRetryTemplate
public RetryTemplate myRetryTemplate() {
return new RetryTemplate();
}
如上例所示,您无需使用@Bean对其进行注解,因为@StreamRetryTemplate是一个合格的@Bean。
如果您的RetryTemplate需要更精确,您可以在ConsumerProperties中按名称指定bean,以将特定的重试bean与每个绑定关联起来。
spring.cloud.stream.bindings.<foo>.consumer.retry-template-name=<your-retry-template-bean-name>绑定器
Spring Cloud Stream 提供了一个 Binder 抽象,用于连接到外部中间件的物理目的地。本节提供了有关 Binder SPI 背后的主要概念、其主要组件和特定于实现细节的信息。
生产者和消费者
下图显示了生产者和消费者的一般关系
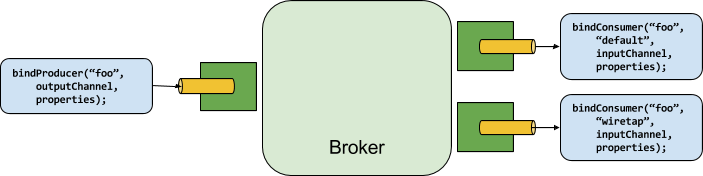
生产者是任何向绑定目标发送消息的组件。绑定目标可以通过该代理的Binder实现绑定到外部消息代理。调用bindProducer()方法时,第一个参数是代理中的目标名称,第二个参数是生产者发送消息的本地目标实例,第三个参数包含用于为该绑定目标创建的适配器中的属性(例如分区键表达式)。
消费者是任何从绑定目的地接收消息的组件。与生产者一样,消费者可以绑定到外部消息代理。调用bindConsumer()方法时,第一个参数是目的地名称,第二个参数提供了一个逻辑消费者组的名称。对于给定目的地的消费者绑定所代表的每个组,都会收到生产者发送到该目的地的每条消息的副本(即,它遵循正常的发布-订阅语义)。如果存在多个以相同组名绑定的消费者实例,则消息会在这些消费者实例之间进行负载均衡,以便生产者发送的每条消息都只由每个组中的单个消费者实例消费(即,它遵循正常的队列语义)。
绑定器 SPI
Binder SPI 由许多接口、开箱即用的实用程序类和发现策略组成,它们提供了一种可插拔的机制,用于连接到外部中间件。
SPI 的关键是Binder接口,它是一种将输入和输出连接到外部中间件的策略。以下列表显示了Binder接口的定义
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
Binding<T> bindConsumer(String bindingName, String group, T inboundBindTarget, C consumerProperties);
Binding<T> bindProducer(String bindingName, T outboundBindTarget, P producerProperties);
}
接口已参数化,提供了许多扩展点
-
输入和输出绑定目标。
-
扩展消费者和生产者属性,允许特定的绑定器实现添加补充属性,这些属性可以以类型安全的方式支持。
典型的绑定器实现包括以下内容
-
一个实现
Binder接口的类; -
一个 Spring
@Configuration类,它创建了一个Binder类型的 bean 以及中间件连接基础设施。 -
在类路径中找到一个
META-INF/spring.binders文件,其中包含一个或多个绑定器定义,如以下示例所示kafka:\ org.springframework.cloud.stream.binder.kafka.config.KafkaBinderConfiguration
如前所述,绑定器抽象也是框架的扩展点之一。因此,如果您在上述列表中找不到合适的绑定器,您可以在 Spring Cloud Stream 之上实现自己的绑定器。在《如何从零开始创建 Spring Cloud Stream Binder》一文中,一位社区成员详细记录了实现自定义绑定器所需的步骤,并提供了示例。这些步骤也在实现自定义绑定器部分中突出显示。 |
绑定器检测
Spring Cloud Stream 依赖于 Binder SPI 的实现来完成将用户代码连接(绑定)到消息代理的任务。每个 Binder 实现通常连接到一种类型的消息系统。
类路径检测
默认情况下,Spring Cloud Stream 依赖于 Spring Boot 的自动配置来配置绑定过程。如果在类路径中找到单个 Binder 实现,Spring Cloud Stream 会自动使用它。例如,旨在仅绑定到 RabbitMQ 的 Spring Cloud Stream 项目可以添加以下依赖项
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>有关其他绑定器依赖项的特定 Maven 坐标,请参阅该绑定器实现的文档。
类路径上的多个绑定器
当类路径上存在多个绑定器时,应用程序必须指明每个目的地绑定使用哪个绑定器。每个绑定器配置都包含一个META-INF/spring.binders文件,这是一个简单的属性文件,如以下示例所示
rabbit:\
org.springframework.cloud.stream.binder.rabbit.config.RabbitServiceAutoConfiguration其他提供的绑定器实现(如 Kafka)也有类似的文件,并且自定义绑定器实现也应提供它们。键表示绑定器实现的标识名称,而值是配置类的逗号分隔列表,每个配置类都包含一个且只有一个org.springframework.cloud.stream.binder.Binder类型的 bean 定义。
绑定器选择可以全局执行,使用spring.cloud.stream.defaultBinder属性(例如,spring.cloud.stream.defaultBinder=rabbit),也可以单独执行,通过在每个绑定上配置绑定器。例如,一个处理器应用程序(分别具有名为input和output的读写绑定)从 Kafka 读取并写入 RabbitMQ,可以指定以下配置
spring.cloud.stream.bindings.input.binder=kafka
spring.cloud.stream.bindings.output.binder=rabbit连接到多个系统
默认情况下,绑定器共享应用程序的 Spring Boot 自动配置,因此会创建类路径上找到的每个绑定器的一个实例。如果您的应用程序应连接到多个相同类型的代理,您可以指定多个绑定器配置,每个配置都有不同的环境设置。
打开显式绑定器配置会完全禁用默认绑定器配置过程。如果您这样做,所有使用的绑定器都必须包含在配置中。旨在透明使用 Spring Cloud Stream 的框架可能会创建可以通过名称引用的绑定器配置,但它们不会影响默认绑定器配置。为了做到这一点,绑定器配置可以将其defaultCandidate标志设置为 false(例如,spring.cloud.stream.binders.<configurationName>.defaultCandidate=false)。这表示一个独立于默认绑定器配置过程而存在的配置。 |
以下示例显示了一个处理器应用程序的典型配置,该应用程序连接到两个 RabbitMQ 代理实例
spring:
cloud:
stream:
bindings:
input:
destination: thing1
binder: rabbit1
output:
destination: thing2
binder: rabbit2
binders:
rabbit1:
type: rabbit
environment:
spring:
rabbitmq:
host: <host1>
rabbit2:
type: rabbit
environment:
spring:
rabbitmq:
host: <host2>特定绑定器的environment属性也可以用于任何 Spring Boot 属性,包括spring.main.sources,这对于为特定绑定器添加额外配置很有用,例如覆盖自动配置的 bean。 |
例如;
environment:
spring:
main:
sources: com.acme.config.MyCustomBinderConfiguration要为特定绑定器环境激活特定配置文件,您应该使用spring.profiles.active属性
environment:
spring:
profiles:
active: myBinderProfile在多绑定器应用程序中自定义绑定器
当应用程序中有多个绑定器并希望自定义绑定器时,可以通过提供BinderCustomizer实现来实现。在单个绑定器的应用程序中,不需要此特殊自定义器,因为绑定器上下文可以直接访问自定义 bean。但是,在多绑定器场景中,情况并非如此,因为不同的绑定器存在于不同的应用程序上下文中。通过提供BinderCustomizer接口的实现,绑定器,尽管位于不同的应用程序上下文中,将接收到自定义。Spring Cloud Stream 确保在应用程序开始使用绑定器之前进行自定义。用户必须检查绑定器类型,然后应用必要的自定义。
这是一个提供BinderCustomizer bean 的示例。
@Bean
public BinderCustomizer binderCustomizer() {
return (binder, binderName) -> {
if (binder instanceof KafkaMessageChannelBinder kafkaMessageChannelBinder) {
kafkaMessageChannelBinder.setRebalanceListener(...);
}
else if (binder instanceof KStreamBinder) {
...
}
else if (binder instanceof RabbitMessageChannelBinder) {
...
}
};
}
请注意,当存在多个相同类型的绑定器实例时,可以使用绑定器名称来过滤自定义。
绑定可视化和控制
Spring Cloud Stream 通过 Actuator 端点和编程方式支持绑定的可视化和控制。
编程方式
自版本 3.1 起,我们公开了 org.springframework.cloud.stream.binding.BindingsLifecycleController,它注册为 bean,一旦注入即可用于控制单个绑定的生命周期
例如,查看一个测试用例的片段。如您所见,我们从 spring 应用程序上下文检索 BindingsLifecycleController 并执行单个方法来控制 echo-in-0 绑定的生命周期。
BindingsLifecycleController bindingsController = context.getBean(BindingsLifecycleController.class);
Binding binding = bindingsController.queryState("echo-in-0");
assertThat(binding.isRunning()).isTrue();
bindingsController.changeState("echo-in-0", State.STOPPED);
//Alternative way of changing state. For convenience we expose start/stop and pause/resume operations.
//bindingsController.stop("echo-in-0")
assertThat(binding.isRunning()).isFalse();
执行器
由于 Actuator 和 Web 是可选的,您必须首先添加其中一个 Web 依赖项以及手动添加 Actuator 依赖项。以下示例展示了如何添加 Web 框架的依赖项
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>以下示例展示了如何添加 WebFlux 框架的依赖项
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>您可以如下添加 Actuator 依赖项
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>要在 Cloud Foundry 中运行 Spring Cloud Stream 2.0 应用程序,您必须将 spring-boot-starter-web 和 spring-boot-starter-actuator 添加到类路径中。否则,应用程序将因健康检查失败而无法启动。 |
您还必须通过设置以下属性来启用bindings执行器端点:--management.endpoints.web.exposure.include=bindings。
一旦这些先决条件得到满足。应用程序启动时,您应该在日志中看到以下内容
: Mapped "{[/actuator/bindings/{name}],methods=[POST]. . .
: Mapped "{[/actuator/bindings],methods=[GET]. . .
: Mapped "{[/actuator/bindings/{name}],methods=[GET]. . .
要可视化当前绑定,请访问以下 URL:http://<host>:<port>/actuator/bindings
或者,要查看单个绑定,请访问以下类似 URL 之一:http://<host>:<port>/actuator/bindings/<bindingName>;
您还可以通过向相同的 URL 发送 POST 请求,并在 JSON 中提供 state 参数来停止、启动、暂停和恢复单个绑定,如以下示例所示
curl -d '{"state":"STOPPED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"STARTED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"PAUSED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"RESUMED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
PAUSED 和 RESUMED 仅在相应的绑定器及其底层技术支持时才有效。否则,您会在日志中看到警告消息。目前,只有 Kafka 和 [Solace](https://github.com/SolaceProducts/solace-spring-cloud/tree/master/solace-spring-cloud-starters/solace-spring-cloud-stream-starter#consumer-bindings-pauseresume) 绑定器支持 PAUSED 和 RESUMED 状态。 |
绑定器配置属性
以下属性在自定义绑定器配置时可用。这些属性通过org.springframework.cloud.stream.config.BinderProperties公开
它们必须以spring.cloud.stream.binders.<configurationName>为前缀。
- 类型
-
绑定器类型。它通常引用类路径上找到的绑定器之一——特别是
META-INF/spring.binders文件中的一个键。默认情况下,它与配置名称具有相同的值。
- 继承环境
-
配置是否继承应用程序自身的环境。
默认值:
true。 - 环境
-
用于定制绑定器环境的一组属性的根。当设置此属性时,创建绑定器的上下文不是应用程序上下文的子上下文。此设置允许绑定器组件和应用程序组件之间完全分离。
默认值:
空。 - 默认候选
-
绑定器配置是否是作为默认绑定器的候选,或者只能在明确引用时使用。此设置允许添加绑定器配置而不干扰默认处理。
默认值:
true。
实现自定义绑定器
为了实现自定义Binder,您只需要
-
添加所需的依赖项
-
提供 ProvisioningProvider 实现
-
提供 MessageProducer 实现
-
提供 MessageHandler 实现
-
提供 Binder 实现
-
创建绑定器配置
-
在 META-INF/spring.binders 中定义您的绑定器
添加所需的依赖项
将spring-cloud-stream依赖项添加到您的项目中(例如,对于 Maven)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
<version>${spring.cloud.stream.version}</version>
</dependency>提供 ProvisioningProvider 实现
ProvisioningProvider负责消费者和生产者目标的供应,并且需要将 application.yml 或 application.properties 文件中包含的逻辑目标转换为物理目标引用。
以下是 ProvisioningProvider 实现的示例,它只修剪通过输入/输出绑定配置提供的目的地
public class FileMessageBinderProvisioner implements ProvisioningProvider<ConsumerProperties, ProducerProperties> {
@Override
public ProducerDestination provisionProducerDestination(
final String name,
final ProducerProperties properties) {
return new FileMessageDestination(name);
}
@Override
public ConsumerDestination provisionConsumerDestination(
final String name,
final String group,
final ConsumerProperties properties) {
return new FileMessageDestination(name);
}
private class FileMessageDestination implements ProducerDestination, ConsumerDestination {
private final String destination;
private FileMessageDestination(final String destination) {
this.destination = destination;
}
@Override
public String getName() {
return destination.trim();
}
@Override
public String getNameForPartition(int partition) {
throw new UnsupportedOperationException("Partitioning is not implemented for file messaging.");
}
}
}
提供 MessageProducer 实现
MessageProducer负责消费事件并将其作为消息传递给配置为消费此类事件的客户端应用程序。
以下是 MessageProducer 实现的一个示例,它扩展了 MessageProducerSupport 抽象,以便轮询与修剪后的目标名称匹配且位于项目路径中的文件,同时还归档已读取的消息并丢弃后续相同的消息
public class FileMessageProducer extends MessageProducerSupport {
public static final String ARCHIVE = "archive.txt";
private final ConsumerDestination destination;
private String previousPayload;
public FileMessageProducer(ConsumerDestination destination) {
this.destination = destination;
}
@Override
public void doStart() {
receive();
}
private void receive() {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
executorService.scheduleWithFixedDelay(() -> {
String payload = getPayload();
if(payload != null) {
Message<String> receivedMessage = MessageBuilder.withPayload(payload).build();
archiveMessage(payload);
sendMessage(receivedMessage);
}
}, 0, 50, MILLISECONDS);
}
private String getPayload() {
try {
List<String> allLines = Files.readAllLines(Paths.get(destination.getName()));
String currentPayload = allLines.get(allLines.size() - 1);
if(!currentPayload.equals(previousPayload)) {
previousPayload = currentPayload;
return currentPayload;
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return null;
}
private void archiveMessage(String payload) {
try {
Files.write(Paths.get(ARCHIVE), (payload + "\n").getBytes(), CREATE, APPEND);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
| 在实现自定义绑定器时,此步骤并非严格强制,因为您始终可以使用已存在的 MessageProducer 实现! |
提供 MessageHandler 实现
MessageHandler 提供生成事件所需的逻辑。
以下是 MessageHandler 实现的一个示例
public class FileMessageHandler implements MessageHandler{
@Override
public void handleMessage(Message<?> message) throws MessagingException {
//write message to file
}
}
| 在实现自定义绑定器时,此步骤并非严格强制,因为您始终可以使用已存在的 MessageHandler 实现! |
提供 Binder 实现
您现在能够提供自己的Binder抽象实现。这可以通过以下方式轻松完成
-
扩展
AbstractMessageChannelBinder类 -
将您的 ProvisioningProvider 指定为 AbstractMessageChannelBinder 的泛型参数
-
覆盖
createProducerMessageHandler和createConsumerEndpoint方法
例如。
public class FileMessageBinder extends AbstractMessageChannelBinder<ConsumerProperties, ProducerProperties, FileMessageBinderProvisioner> {
public FileMessageBinder(
String[] headersToEmbed,
FileMessageBinderProvisioner provisioningProvider) {
super(headersToEmbed, provisioningProvider);
}
@Override
protected MessageHandler createProducerMessageHandler(
final ProducerDestination destination,
final ProducerProperties producerProperties,
final MessageChannel errorChannel) throws Exception {
return message -> {
String fileName = destination.getName();
String payload = new String((byte[])message.getPayload()) + "\n";
try {
Files.write(Paths.get(fileName), payload.getBytes(), CREATE, APPEND);
} catch (IOException e) {
throw new RuntimeException(e);
}
};
}
@Override
protected MessageProducer createConsumerEndpoint(
final ConsumerDestination destination,
final String group,
final ConsumerProperties properties) throws Exception {
return new FileMessageProducer(destination);
}
}
创建绑定器配置
严格要求您创建一个 Spring 配置来初始化绑定器实现的 bean(以及您可能需要的其他所有 bean)
@Configuration
public class FileMessageBinderConfiguration {
@Bean
@ConditionalOnMissingBean
public FileMessageBinderProvisioner fileMessageBinderProvisioner() {
return new FileMessageBinderProvisioner();
}
@Bean
@ConditionalOnMissingBean
public FileMessageBinder fileMessageBinder(FileMessageBinderProvisioner fileMessageBinderProvisioner) {
return new FileMessageBinder(null, fileMessageBinderProvisioner);
}
}
在 META-INF/spring.binders 中定义您的绑定器
最后,您必须在类路径上的META-INF/spring.binders文件中定义您的绑定器,指定绑定器的名称和您的绑定器配置类的完全限定名称
myFileBinder:\
com.example.springcloudstreamcustombinder.config.FileMessageBinderConfiguration配置选项
Spring Cloud Stream 支持通用配置选项以及绑定和绑定器的配置。一些绑定器允许额外的绑定属性支持中间件特定的功能。
配置选项可以通过 Spring Boot 支持的任何机制提供给 Spring Cloud Stream 应用程序。这包括应用程序参数、环境变量以及 YAML 或 .properties 文件。
绑定服务属性
这些属性通过org.springframework.cloud.stream.config.BindingServiceProperties公开
- spring.cloud.stream.instanceCount
-
应用程序的已部署实例数。必须在生产者端进行分区设置。当使用 RabbitMQ 且 Kafka 的
autoRebalanceEnabled=false时,必须在消费者端进行设置。默认值:
1。 - spring.cloud.stream.instanceIndex
-
应用程序的实例索引:一个从
0到instanceCount - 1的数字。用于 RabbitMQ 和 Kafka(如果autoRebalanceEnabled=false)的分区。在 Cloud Foundry 中自动设置以匹配应用程序的实例索引。 - spring.cloud.stream.dynamicDestinations
-
可以动态绑定(例如,在动态路由场景中)的目标列表。如果设置,则只能绑定列出的目标。
默认值:空(允许绑定任何目的地)。
- spring.cloud.stream.defaultBinder
-
如果配置了多个绑定器,则使用的默认绑定器。参见类路径上的多个绑定器。
默认值:空。
- spring.cloud.stream.overrideCloudConnectors
-
此属性仅适用于
cloud配置文件处于活动状态且应用程序提供了 Spring Cloud Connectors 的情况。如果属性为false(默认值),绑定器会检测合适的绑定服务(例如,Cloud Foundry 中为 RabbitMQ 绑定器绑定的 RabbitMQ 服务)并使用它创建连接(通常通过 Spring Cloud Connectors)。当设置为true时,此属性指示绑定器完全忽略绑定服务并依赖 Spring Boot 属性(例如,依赖环境中为 RabbitMQ 绑定器提供的spring.rabbitmq.*属性)。此属性的典型用法是在连接到多个系统时嵌套在自定义环境中。默认值:
false。 - spring.cloud.stream.bindingRetryInterval
-
重试绑定创建的间隔(以秒为单位),例如,当绑定器不支持延迟绑定并且代理(例如 Apache Kafka)关闭时。将其设置为零,将此类情况视为致命,阻止应用程序启动。
默认值:
30
绑定属性
绑定属性通过spring.cloud.stream.bindings.<bindingName>.<property>=<value>格式提供。<bindingName>表示正在配置的绑定的名称。
例如,对于以下函数
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
输入绑定名为uppercase-in-0,输出绑定名为uppercase-out-0。更多详细信息请参见绑定和绑定名称。
为避免重复,Spring Cloud Stream 支持为所有绑定设置值,格式为spring.cloud.stream.default.<property>=<value>和spring.cloud.stream.default.<producer|consumer>.<property>=<value>,用于通用绑定属性。
当涉及避免扩展绑定属性的重复时,应使用此格式 - spring.cloud.stream.<binder-type>.default.<producer|consumer>.<property>=<value>。
通用绑定属性
这些属性通过org.springframework.cloud.stream.config.BindingProperties公开
以下绑定属性适用于输入和输出绑定,并且必须以spring.cloud.stream.bindings.<bindingName>.为前缀(例如,spring.cloud.stream.bindings.uppercase-in-0.destination=ticktock)。
默认值可以通过使用spring.cloud.stream.default前缀设置(例如spring.cloud.stream.default.contentType=application/json)。
- 目的地
-
绑定在已绑定中间件上的目标目的地(例如,RabbitMQ 交换器或 Kafka 主题)。如果绑定表示消费者绑定(输入),则可以绑定到多个目的地,目的地名称可以指定为逗号分隔的
String值。否则,将使用实际的绑定名称。此属性的默认值不能被覆盖。 - group
-
绑定的消费者组。仅适用于入站绑定。参见消费者组。
默认值:
null(表示匿名消费者)。 - contentType
-
此绑定的内容类型。参见
内容类型协商。默认值:
application/json。 - 绑定器
-
此绑定使用的绑定器。有关详细信息,请参见
类路径上的多个绑定器。默认值:
null(如果存在,则使用默认绑定器)。
消费者属性
这些属性通过org.springframework.cloud.stream.binder.ConsumerProperties公开
以下绑定属性仅适用于输入绑定,并且必须以spring.cloud.stream.bindings.<bindingName>.consumer.为前缀(例如,spring.cloud.stream.bindings.input.consumer.concurrency=3)。
默认值可以通过使用spring.cloud.stream.default.consumer前缀设置(例如,spring.cloud.stream.default.consumer.headerMode=none)。
- 自动启动
-
指示此消费者是否需要自动启动
默认值:
true。 - concurrency
-
入站消费者的并发性。
默认值:
1。 - 已分区
-
消费者是否从分区生产者接收数据。
默认值:
false。 - 头模式
-
当设置为
none时,禁用输入端的头解析。仅对不支持原生消息头且需要头嵌入的消息中间件有效。此选项在从非 Spring Cloud Stream 应用程序消费数据且不支持原生头时非常有用。当设置为headers时,它使用中间件的原生头机制。当设置为embeddedHeaders时,它将头嵌入到消息 payload 中。默认值:取决于绑定器实现。
- maxAttempts
-
如果处理失败,处理消息的尝试次数(包括第一次)。设置为
1以禁用重试。默认值:
3。 - backOffInitialInterval
-
重试时的回退初始间隔。
默认值:
1000。 - backOffMaxInterval
-
最大回退间隔。
默认值:
10000。 - backOffMultiplier
-
回退乘数。
默认值:
2.0。 - defaultRetryable
-
侦听器抛出的未列在
retryableExceptions中的异常是否可重试。默认值:
true。 - 实例计数
-
当设置为大于或等于零的值时,它允许自定义此消费者的实例计数(如果与
spring.cloud.stream.instanceCount不同)。当设置为负值时,它默认为spring.cloud.stream.instanceCount。如果提供了instanceIndexList则忽略。有关更多信息,请参见实例索引和实例计数。默认值:
-1。 - 实例索引
-
当设置为大于或等于零的值时,它允许自定义此消费者的实例索引(如果与
spring.cloud.stream.instanceIndex不同)。当设置为负值时,它默认为spring.cloud.stream.instanceIndex。如果提供了instanceIndexList则忽略。有关更多信息,请参见实例索引和实例计数。默认值:
-1。 - 实例索引列表
-
与不支持原生分区(如 RabbitMQ)的绑定器一起使用;允许应用程序实例从多个分区消费。
默认值:空。
- retryableExceptions
-
一个映射,键是 Throwable 类名,值是布尔值。指定那些将或不会重试的异常(及其子类)。另请参见
defaultRetriable。示例:spring.cloud.stream.bindings.input.consumer.retryable-exceptions.java.lang.IllegalStateException=false。默认值:空。
- useNativeDecoding
-
当设置为
true时,入站消息由客户端库直接反序列化,客户端库必须相应地配置(例如,设置适当的 Kafka 生产者值反序列化器)。当使用此配置时,入站消息的解组不基于绑定的contentType。当使用原生解码时,生产者有责任使用适当的编码器(例如,Kafka 生产者值序列化器)来序列化出站消息。此外,当使用原生编码和解码时,headerMode=embeddedHeaders属性将被忽略,并且头不会嵌入到消息中。参见生产者属性useNativeEncoding。默认值:
false。 - 多路复用
-
当设置为 true 时,底层绑定器将原生复用相同输入绑定上的目的地。
默认值:
false。
高级消费者配置
对于消息驱动消费者的底层消息监听器容器的高级配置,请向应用程序上下文添加单个ListenerContainerCustomizer bean。它将在应用上述属性后被调用,并可用于设置其他属性。类似地,对于轮询消费者,添加一个MessageSourceCustomizer bean。
以下是 RabbitMQ 绑定器的一个示例
@Bean
public ListenerContainerCustomizer<AbstractMessageListenerContainer> containerCustomizer() {
return (container, dest, group) -> container.setAdviceChain(advice1, advice2);
}
@Bean
public MessageSourceCustomizer<AmqpMessageSource> sourceCustomizer() {
return (source, dest, group) -> source.setPropertiesConverter(customPropertiesConverter);
}
生产者属性
这些属性通过org.springframework.cloud.stream.binder.ProducerProperties公开
以下绑定属性仅适用于输出绑定,并且必须以spring.cloud.stream.bindings.<bindingName>.producer.为前缀(例如,spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=headers.id)。
默认值可以通过使用前缀spring.cloud.stream.default.producer设置(例如,spring.cloud.stream.default.producer.partitionKeyExpression=headers.id)。
- 自动启动
-
指示此消费者是否需要自动启动
默认值:
true。 - 分区键表达式
-
一个 SpEL 表达式,用于确定如何分区出站数据。如果设置,此绑定上的出站数据将进行分区。
partitionCount必须设置为大于 1 的值才能生效。参见分区支持。默认值:null。
- 分区键提取器名称
-
实现
PartitionKeyExtractorStrategy的 bean 的名称。用于提取用于计算分区 ID 的键(参见“partitionSelector*”)。与“partitionKeyExpression”互斥。默认值:null。
- 分区选择器名称
-
实现
PartitionSelectorStrategy的 bean 的名称。用于根据分区键(参见“partitionKeyExtractor*”)确定分区 ID。与“partitionSelectorExpression”互斥。默认值:null。
- 分区选择器表达式
-
用于自定义分区选择的 SpEL 表达式。如果两者均未设置,则分区选择为
hashCode(key) % partitionCount,其中key通过partitionKeyExpression计算。默认值:
null。 - 分区计数
-
如果启用了分区,则数据的目标分区数。如果生产者已分区,则必须设置为大于 1 的值。在 Kafka 上,它被解释为提示。将使用此值和目标主题的分区计数中较大的一个。
默认值:
1。 - 所需组
-
一个逗号分隔的组列表,生产者必须确保消息传递到这些组,即使它们是在创建之后启动的(例如,通过在 RabbitMQ 中预创建持久队列)。
- 头模式
-
当设置为
none时,它禁用输出端的头部嵌入。它仅对不支持消息头部原生且需要头部嵌入的消息中间件有效。此选项在为非 Spring Cloud Stream 应用程序生成数据且不支持原生头部时非常有用。当设置为headers时,它使用中间件的原生头部机制。当设置为embeddedHeaders时,它将头部嵌入到消息 payload 中。默认值:取决于绑定器实现。
- useNativeEncoding
-
当设置为
true时,出站消息由客户端库直接序列化,该客户端库必须相应地配置(例如,设置适当的 Kafka 生产者值序列化器)。当使用此配置时,出站消息的编组不基于绑定的contentType。当使用原生编码时,消费者有责任使用适当的解码器(例如,Kafka 消费者值反序列化器)来反序列化入站消息。此外,当使用原生编码和解码时,headerMode=embeddedHeaders属性将被忽略,并且头不会嵌入到消息中。参见消费者属性useNativeDecoding。默认值:
false。 - 错误通道已启用
-
当设置为 true 时,如果绑定器支持异步发送结果,发送失败将被发送到目标错误通道。有关详细信息,请参见错误处理。
默认值: false。
高级生产者配置
在某些情况下,生产者属性不足以在绑定器中正确配置生产消息处理程序,或者您可能更喜欢在配置此类生产消息处理程序时采用编程方法。无论出于何种原因,spring-cloud-stream 都提供了ProducerMessageHandlerCustomizer来实现它。
@FunctionalInterface
public interface ProducerMessageHandlerCustomizer<H extends MessageHandler> {
/**
* Configure a {@link MessageHandler} that is being created by the binder for the
* provided destination name.
* @param handler the {@link MessageHandler} from the binder.
* @param destinationName the bound destination name.
*/
void configure(H handler, String destinationName);
}
如您所见,它允许您访问实际的生产MessageHandler实例,您可以根据需要进行配置。您所需要做的就是提供此策略的实现并将其配置为@Bean。
内容类型协商
数据转换是任何消息驱动微服务架构的核心功能之一。鉴于在 Spring Cloud Stream 中,此类数据表示为 Spring Message,消息在到达目的地之前可能需要转换为所需的形状或大小。这需要两个原因
-
将传入消息的内容转换为与应用程序提供的处理程序的签名匹配。
-
将传出消息的内容转换为线路格式。
线路格式通常是byte[](Kafka 和 Rabbit 绑定器都是如此),但它由绑定器实现控制。
在 Spring Cloud Stream 中,消息转换通过org.springframework.messaging.converter.MessageConverter完成。
| 作为后续详细信息的补充,您可能还希望阅读以下博客文章。 |
机制
为了更好地理解内容类型协商的机制和必要性,我们以以下消息处理程序为例,看一个非常简单的用例
public Function<Person, String> personFunction {..}
| 为简单起见,我们假设这是应用程序中唯一的处理程序函数(我们假设没有内部管道)。 |
前面示例中显示的处理程序期望一个Person对象作为参数,并生成一个String类型作为输出。为了使框架成功地将传入的Message作为参数传递给此处理程序,它必须以某种方式将Message类型的有效负载从线路格式转换为Person类型。换句话说,框架必须找到并应用适当的MessageConverter。为了实现这一点,框架需要用户提供一些指令。其中一个指令已经由处理程序方法本身的签名(Person类型)提供。因此,理论上,这应该(在某些情况下也确实是)足够的。但是,对于大多数用例,为了选择适当的MessageConverter,框架需要额外的信息。缺失的这部分信息是contentType。
Spring Cloud Stream 提供了三种机制来定义contentType(按优先级顺序)
-
HEADER:
contentType可以通过消息本身进行通信。通过提供contentType头,您可以声明用于定位和应用适当MessageConverter的内容类型。 -
绑定:
contentType可以通过设置spring.cloud.stream.bindings.input.content-type属性来为每个目标绑定设置。属性名中的 input部分对应于目的地的实际名称(在本例中为“input”)。这种方法允许您根据每个绑定声明用于定位和应用适当MessageConverter的内容类型。 -
默认值:如果
contentType不存在于Message头或绑定中,则使用默认的application/json内容类型来定位和应用适当的MessageConverter。
如前所述,前面的列表还展示了在发生冲突时的优先级顺序。例如,通过头提供的内容类型优先于任何其他内容类型。对于每个绑定设置的内容类型也同样适用,这实际上允许您覆盖默认内容类型。但是,它也提供了一个合理的默认值(这是根据社区反馈确定的)。
将application/json设为默认值的另一个原因是,分布式微服务架构驱动的互操作性需求,其中生产者和消费者不仅运行在不同的 JVM 中,而且还可以运行在不同的非 JVM 平台上。
当非空处理程序方法返回时,如果返回值为Message,则该Message成为有效载荷。但是,当返回值不是Message时,新的Message将以返回值作为有效载荷构建,同时继承输入Message中的头,减去由SpringIntegrationProperties.messageHandlerNotPropagatedHeaders定义或过滤的头。默认情况下,那里只有一个头集:contentType。这意味着新的Message没有设置contentType头,从而确保contentType可以演变。您始终可以选择不从处理程序方法返回Message,在那里您可以注入您希望的任何头。
如果存在内部管道,消息将通过相同的转换过程发送到下一个处理程序。但是,如果没有内部管道或已到达管道末尾,则消息将发送回输出目的地。
内容类型与参数类型
如前所述,为了使框架选择适当的MessageConverter,它需要参数类型,并且可选地需要内容类型信息。选择适当MessageConverter的逻辑驻留在参数解析器(HandlerMethodArgumentResolvers)中,这些解析器在调用用户定义处理程序方法之前触发(此时框架知道实际参数类型)。如果参数类型与当前有效负载的类型不匹配,框架将委托给预配置的MessageConverter堆栈,以查看它们中是否有任何一个可以转换有效负载。如您所见,MessageConverter 的Object fromMessage(Message<?> message, Class<?> targetClass);操作将targetClass作为其参数之一。框架还确保提供的Message始终包含contentType头。当之前没有contentType头时,它会注入每个绑定contentType头或默认contentType头。contentType参数类型的组合是框架确定消息是否可以转换为目标类型的机制。如果没有找到适当的MessageConverter,则会抛出异常,您可以通过添加自定义MessageConverter来处理(请参阅用户定义的消息转换器)。
但是,如果有效负载类型与处理程序方法声明的目标类型匹配呢?在这种情况下,无需进行转换,有效负载将原样传递。尽管这听起来非常简单和合乎逻辑,但请记住将Message<?>或Object作为参数的处理程序方法。通过将目标类型声明为Object(在 Java 中是所有对象的instanceof),您实际上放弃了转换过程。
不要期望Message仅根据contentType转换为其他类型。请记住,contentType是对目标类型的补充。如果您愿意,可以提供一个提示,MessageConverter可能会或可能不会将其考虑在内。 |
消息转换器
MessageConverters 定义了两种方法
Object fromMessage(Message<?> message, Class<?> targetClass);
Message<?> toMessage(Object payload, @Nullable MessageHeaders headers);
理解这些方法的契约及其用法非常重要,特别是在 Spring Cloud Stream 的上下文中。
fromMessage方法将传入的Message转换为参数类型。Message的有效负载可以是任何类型,并且由MessageConverter的实际实现来支持多种类型。例如,一些 JSON 转换器可能支持byte[]、String等有效负载类型。当应用程序包含内部管道(即,输入 → 处理程序1 → 处理程序2 →. . . → 输出)且上游处理程序的输出导致的消息可能不是初始线路格式时,这一点很重要。
但是,toMessage 方法有一个更严格的契约,并且必须始终将 Message 转换为线路格式:byte[]。
因此,出于所有目的(尤其是在实现自己的转换器时),您将这两种方法视为具有以下签名
Object fromMessage(Message<?> message, Class<?> targetClass);
Message<byte[]> toMessage(Object payload, @Nullable MessageHeaders headers);
提供的消息转换器
如前所述,框架已经提供了一系列 MessageConverter 来处理大多数常见用例。以下列表描述了提供的 MessageConverter,按优先级顺序(使用第一个起作用的 MessageConverter)
-
JsonMessageConverter:顾名思义,当contentType为application/json(默认)时,它支持将Message的有效负载转换为/从 POJO。 -
ByteArrayMessageConverter:支持当contentType为application/octet-stream时,将Message的 payload 从byte[]转换为byte[]。它本质上是一个直通,主要用于向后兼容性。 -
ObjectStringMessageConverter:当contentType为text/plain时,支持将任何类型转换为String。它调用 Object 的toString()方法,或者如果 payload 是byte[],则调用新的String(byte[])。
当找不到合适的转换器时,框架会抛出异常。发生这种情况时,您应该检查您的代码和配置,并确保您没有遗漏任何东西(即,确保您通过绑定或头提供了contentType)。但是,最有可能的是,您发现了一些不常见的情况(例如自定义contentType),并且当前提供的MessageConverters堆栈不知道如何转换。如果是这种情况,您可以添加自定义MessageConverter。请参阅用户定义的消息转换器。
用户定义的消息转换器
Spring Cloud Stream 公开了一种机制来定义和注册额外的MessageConverter。要使用它,请实现org.springframework.messaging.converter.MessageConverter,并将其配置为@Bean。然后它将被添加到现有的MessageConverter堆栈中。
重要的是要理解自定义 MessageConverter 实现被添加到现有栈的头部。因此,自定义 MessageConverter 实现优先于现有实现,这使您可以覆盖和添加现有转换器。 |
以下示例展示了如何创建消息转换器 Bean 以支持名为 application/bar 的新内容类型
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter customMessageConverter() {
return new MyCustomMessageConverter();
}
}
public class MyCustomMessageConverter extends AbstractMessageConverter {
public MyCustomMessageConverter() {
super(new MimeType("application", "bar"));
}
@Override
protected boolean supports(Class<?> clazz) {
return (Bar.class.equals(clazz));
}
@Override
protected Object convertFromInternal(Message<?> message, Class<?> targetClass, Object conversionHint) {
Object payload = message.getPayload();
return (payload instanceof Bar ? payload : new Bar((byte[]) payload));
}
}
应用间通信
Spring Cloud Stream 实现了应用程序之间的通信。应用程序间通信是一个复杂的问题,涉及以下几个方面
连接多个应用程序实例
虽然 Spring Cloud Stream 使单个 Spring Boot 应用程序轻松连接到消息系统,但 Spring Cloud Stream 的典型场景是创建多应用程序管道,其中微服务应用程序相互发送数据。您可以通过关联“相邻”应用程序的输入和输出目的地来实现此场景。
假设设计要求时间源应用程序向日志接收器应用程序发送数据。您可以为这两个应用程序中的绑定使用一个名为ticktock的公共目的地。
时间源(绑定名为output)将设置以下属性
spring.cloud.stream.bindings.output.destination=ticktock
日志接收器(绑定名为input)将设置以下属性
spring.cloud.stream.bindings.input.destination=ticktock
实例索引和实例计数
当 Spring Cloud Stream 应用程序进行横向扩展时,每个实例都可以接收有关有多少其他相同应用程序实例以及其自身的实例索引的信息。Spring Cloud Stream 通过spring.cloud.stream.instanceCount和spring.cloud.stream.instanceIndex属性来实现这一点。例如,如果有一个 HDFS sink 应用程序的三个实例,所有三个实例的spring.cloud.stream.instanceCount都设置为3,并且各个应用程序的spring.cloud.stream.instanceIndex分别设置为0、1和2。
当 Spring Cloud Stream 应用程序通过 Spring Cloud Data Flow 部署时,这些属性会自动配置;当 Spring Cloud Stream 应用程序独立启动时,这些属性必须正确设置。默认情况下,spring.cloud.stream.instanceCount为1,spring.cloud.stream.instanceIndex为0。
在横向扩展场景中,正确配置这两个属性对于解决分区行为(参见下文)至关重要,并且某些绑定器(例如 Kafka 绑定器)始终需要这两个属性,以确保数据在多个消费者实例之间正确拆分。
分区
Spring Cloud Stream 中的分区包含两个任务
为分区配置输出绑定
您可以通过设置其partitionKeyExpression或partitionKeyExtractorName属性之一以及partitionCount属性来配置输出绑定以发送分区数据。
例如,以下是有效且典型的配置
spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=headers.id spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
根据上述示例配置,数据将使用以下逻辑发送到目标分区。
对于发送到分区输出绑定的每条消息,都会根据partitionKeyExpression计算分区键的值。partitionKeyExpression是一个 SpEL 表达式,它根据出站消息进行评估(在前面的示例中,它是消息头中id的值),用于提取分区键。
如果 SpEL 表达式不足以满足您的需求,您可以通过提供org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy的实现并将其配置为 bean(通过使用@Bean注解)来计算分区键值。如果应用程序上下文中存在多个org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy类型的 bean,您可以通过partitionKeyExtractorName属性指定其名称来进一步过滤,如以下示例所示
--spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExtractorName=customPartitionKeyExtractor
--spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
. . .
@Bean
public CustomPartitionKeyExtractorClass customPartitionKeyExtractor() {
return new CustomPartitionKeyExtractorClass();
}在 Spring Cloud Stream 的早期版本中,您可以通过设置spring.cloud.stream.bindings.output.producer.partitionKeyExtractorClass属性来指定org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy的实现。自 3.0 版本起,此属性已移除。 |
一旦计算出消息键,分区选择过程将确定目标分区,其值介于0和partitionCount - 1之间。适用于大多数场景的默认计算基于以下公式:key.hashCode() % partitionCount。这可以在绑定上进行自定义,方法是设置一个 SpEL 表达式以根据“key”进行评估(通过partitionSelectorExpression属性),或者将org.springframework.cloud.stream.binder.PartitionSelectorStrategy的实现配置为 bean(通过使用@Bean注解)。与PartitionKeyExtractorStrategy类似,当应用程序上下文中存在多个此类型的 bean 时,您可以使用spring.cloud.stream.bindings.output.producer.partitionSelectorName属性进一步过滤,如以下示例所示
--spring.cloud.stream.bindings.func-out-0.producer.partitionSelectorName=customPartitionSelector
. . .
@Bean
public CustomPartitionSelectorClass customPartitionSelector() {
return new CustomPartitionSelectorClass();
}在 Spring Cloud Stream 的早期版本中,您可以通过设置spring.cloud.stream.bindings.output.producer.partitionSelectorClass属性来指定org.springframework.cloud.stream.binder.PartitionSelectorStrategy的实现。自 3.0 版本起,此属性已移除。 |
为分区配置输入绑定
通过设置其partitioned属性以及应用程序本身的instanceIndex和instanceCount属性,配置输入绑定(绑定名称为uppercase-in-0)以接收分区数据,如以下示例所示
spring.cloud.stream.bindings.uppercase-in-0.consumer.partitioned=true spring.cloud.stream.instanceIndex=3 spring.cloud.stream.instanceCount=5
instanceCount 值表示数据应在其中分区的应用程序实例总数。instanceIndex 在多个实例中必须是唯一值,其值介于 0 和 instanceCount - 1 之间。实例索引有助于每个应用程序实例识别其接收数据的唯一分区。使用不原生支持分区的技术的绑定器需要它。例如,对于 RabbitMQ,每个分区都有一个队列,队列名称包含实例索引。对于 Kafka,如果 autoRebalanceEnabled 为 true(默认值),Kafka 会负责在实例之间分发分区,并且不需要这些属性。如果 autoRebalanceEnabled 设置为 false,绑定器将使用 instanceCount 和 instanceIndex 来确定实例订阅的分区(您必须至少有与实例一样多的分区)。绑定器会分配分区而不是 Kafka。如果您希望特定分区的消息始终发送到同一个实例,这可能会很有用。当绑定器配置需要它们时,正确设置这两个值以确保所有数据都被消费并且应用程序实例接收到互斥的数据集非常重要。
虽然在独立情况下为分区数据处理使用多个实例可能设置复杂,但 Spring Cloud Dataflow 可以通过正确填充输入和输出值,并让您依赖运行时基础设施提供实例索引和实例计数信息来显著简化该过程。
测试
Spring Cloud Stream 提供支持,无需连接到消息系统即可测试您的微服务应用程序。
Spring Integration 测试绑定器
Spring Cloud Stream 提供了一个测试绑定器,您可以使用它来测试各种应用程序组件,而无需实际的真实绑定器实现或消息代理。
这个测试绑定器充当单元测试和集成测试之间的桥梁,它基于 Spring Integration 框架作为 JVM 内的消息代理,本质上为您提供了两全其美的好处——一个真实的绑定器,但无需网络。
测试绑定器配置
要启用 Spring Integration 测试绑定器,您只需将其添加为依赖项。
添加所需依赖项
下面是所需 Maven POM 条目的示例。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-test-binder</artifactId>
<scope>test</scope>
</dependency>或者对于 build.gradle.kts
testImplementation("org.springframework.cloud:spring-cloud-stream-test-binder")
测试绑定器使用
现在您可以将微服务作为简单的单元测试进行测试
@SpringBootTest
public class SampleStreamTests {
@Autowired
private InputDestination input;
@Autowired
private OutputDestination output;
@Test
public void testEmptyConfiguration() {
this.input.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(output.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
@SpringBootApplication
@Import(TestChannelBinderConfiguration.class)
public static class SampleConfiguration {
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
}
}
如果您需要更多控制权,或者想在同一个测试套件中测试多个配置,您也可以执行以下操作
@EnableAutoConfiguration
public static class MyTestConfiguration {
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
}
. . .
@Test
public void sampleTest() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
MyTestConfiguration.class))
.run("--spring.cloud.function.definition=uppercase")) {
InputDestination source = context.getBean(InputDestination.class);
OutputDestination target = context.getBean(OutputDestination.class);
source.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(target.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
}
对于具有多个绑定和/或多个输入和输出,或者只是想明确指定要发送或接收的目标名称的情况,InputDestination 和 OutputDestination 的 send() 和 receive() 方法已被重写,允许您提供输入和输出目标的名称。
考虑以下示例
@EnableAutoConfiguration
public static class SampleFunctionConfiguration {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
@Bean
public Function<String, String> reverse() {
return value -> new StringBuilder(value).reverse().toString();
}
}
以及实际的测试
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleFunctionConfiguration.class))
.run("--spring.cloud.function.definition=uppercase;reverse")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "uppercase-in-0");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "uppercase-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}
对于具有额外映射属性(例如 destination)的情况,您应该使用这些名称。例如,考虑前面测试的不同版本,其中我们明确地将 uppercase 函数的输入和输出映射到 myInput 和 myOutput 绑定名称
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleFunctionConfiguration.class))
.run(
"--spring.cloud.function.definition=uppercase;reverse",
"--spring.cloud.stream.bindings.uppercase-in-0.destination=myInput",
"--spring.cloud.stream.bindings.uppercase-out-0.destination=myOutput"
)) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "myInput");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "myOutput");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}
测试绑定器和 PollableMessageSource
Spring Integration 测试绑定器还允许您在使用 PollableMessageSource 时编写测试(有关详细信息,请参阅使用轮询消费者)。
但需要理解的重要一点是,轮询不是事件驱动的,PollableMessageSource 是一种公开操作以生成(轮询)消息(单数)的策略。您轮询的频率、使用的线程数或从何处轮询(消息队列或文件系统)完全取决于您;换句话说,您有责任配置 Poller 或 Threads 或消息的实际来源。幸运的是,Spring 有大量的抽象来精确配置这些。
让我们来看一个例子
@Test
public void samplePollingTest() {
ApplicationContext context = new SpringApplicationBuilder(SamplePolledConfiguration.class)
.web(WebApplicationType.NONE)
.run("--spring.jmx.enabled=false", "--spring.cloud.stream.pollable-source=myDestination");
OutputDestination destination = context.getBean(OutputDestination.class);
System.out.println("Message 1: " + new String(destination.receive().getPayload()));
System.out.println("Message 2: " + new String(destination.receive().getPayload()));
System.out.println("Message 3: " + new String(destination.receive().getPayload()));
}
@Import(TestChannelBinderConfiguration.class)
@EnableAutoConfiguration
public static class SamplePolledConfiguration {
@Bean
public ApplicationRunner poller(PollableMessageSource polledMessageSource, StreamBridge output, TaskExecutor taskScheduler) {
return args -> {
taskScheduler.execute(() -> {
for (int i = 0; i < 3; i++) {
try {
if (!polledMessageSource.poll(m -> {
String newPayload = ((String) m.getPayload()).toUpperCase();
output.send("myOutput", newPayload);
})) {
Thread.sleep(2000);
}
}
catch (Exception e) {
// handle failure
}
}
});
};
}
}
上面的(非常粗糙的)示例将以 2 秒间隔生成 3 条消息,将它们发送到 Source 的输出目标,此绑定器将其发送到 OutputDestination,我们从那里检索它们(用于任何断言)。目前,它打印以下内容
Message 1: POLLED DATA
Message 2: POLLED DATA
Message 3: POLLED DATA如您所见,数据是相同的。这是因为此绑定器定义了实际 MessageSource 的默认实现——使用 poll() 操作轮询消息的源。虽然对于大多数测试场景来说已经足够,但在某些情况下您可能希望定义自己的 MessageSource。为此,只需在您的测试配置中配置一个类型为 MessageSource 的 bean,提供您自己的消息源实现。
这是示例
@Bean
public MessageSource<?> source() {
return () -> new GenericMessage<>("My Own Data " + UUID.randomUUID());
}
呈现以下输出;
Message 1: MY OWN DATA 1C180A91-E79F-494F-ABF4-BA3F993710DA
Message 2: MY OWN DATA D8F3A477-5547-41B4-9434-E69DA7616FEE
Message 3: MY OWN DATA 20BF2E64-7FF4-4CB6-A823-4053D30B5C74不要将此 bean 命名为 messageSource,因为它会与 Spring Boot 出于无关原因提供的同名(不同类型)bean 冲突。 |
关于混合使用测试绑定器和常规中间件绑定器进行测试的特别说明
提供基于 Spring Integration 的测试绑定器是为了测试应用程序,而无需涉及实际的基于中间件的绑定器,例如 Kafka 或 RabbitMQ 绑定器。如上文所述,测试绑定器通过依赖内存中的 Spring Integration 通道帮助您快速验证应用程序行为。当测试绑定器存在于测试类路径中时,Spring Cloud Stream 将尝试在需要绑定器进行通信的所有测试目的中使用此绑定器。换句话说,您不能在同一模块中混合使用测试绑定器和常规中间件绑定器进行测试。在使用测试绑定器测试应用程序后,如果您想继续使用实际的中间件绑定器进行进一步的集成测试,建议将使用实际绑定器的测试添加到单独的模块中,以便这些测试可以与实际中间件建立适当的连接,而不是依赖测试绑定器提供的内存通道。
健康指标
Spring Cloud Stream 为绑定器提供了一个健康指标。它以 binders 名称注册,可以通过设置 management.health.binders.enabled 属性来启用或禁用。
要启用健康检查,您首先需要通过包含其依赖项来同时启用“web”和“actuator”(请参阅绑定可视化和控制)
如果应用程序没有明确设置 management.health.binders.enabled,则 management.health.defaults.enabled 将匹配为 true,并且绑定器健康指标将被启用。如果您想完全禁用健康指标,则必须将 management.health.binders.enabled 设置为 false。
您可以使用 Spring Boot 执行器健康端点来访问健康指标 - /actuator/health。默认情况下,当您访问上述端点时,您将只收到顶级应用程序状态。为了从绑定器特定的健康指标中接收完整详细信息,您需要在应用程序中包含值为 ALWAYS 的属性 management.endpoint.health.show-details。
健康指标是绑定器特定的,某些绑定器实现可能不一定会提供健康指标。
如果您想完全禁用所有开箱即用的健康指标,并提供自己的健康指标,您可以通过将属性 management.health.binders.enabled 设置为 false,然后在应用程序中提供自己的 HealthIndicator bean 来实现。在这种情况下,Spring Boot 的健康指标基础设施仍将识别这些自定义 bean。即使您不禁用绑定器健康指标,您仍然可以通过在开箱即用健康检查的基础上提供自己的 HealthIndicator bean 来增强健康检查。
当同一个应用程序中有多个绑定器时,健康指标默认启用,除非应用程序通过将 management.health.binders.enabled 设置为 false 来关闭它们。在这种情况下,如果用户希望禁用部分绑定器的健康检查,则应在多绑定器配置的环境中将 management.health.binders.enabled 设置为 false。有关如何提供特定于环境的属性的详细信息,请参阅连接到多个系统。
如果类路径中存在多个绑定器,但并非所有绑定器都在应用程序中使用,这可能会在健康指标方面导致一些问题。关于如何执行健康检查可能存在特定于实现的详细信息。例如,如果绑定器没有注册任何目标,Kafka 绑定器可能会将状态判定为 DOWN。
我们举一个具体的例子。假设您的类路径中同时存在 Kafka 和 Kafka Streams 绑定器,但在应用程序代码中只使用 Kafka Streams 绑定器,即只使用 Kafka Streams 绑定器提供绑定。由于 Kafka 绑定器未使用,并且它有特定的检查来查看是否注册了任何目标,因此绑定器健康检查将失败。顶级应用程序健康检查状态将报告为 DOWN。在这种情况下,您可以简单地从应用程序中删除 Kafka 绑定器的依赖项,因为您没有使用它。
示例
有关 Spring Cloud Stream 示例,请参阅 GitHub 上的 spring-cloud-stream-samples 仓库。
在 CloudFoundry 上部署流应用程序
在 CloudFoundry 上,服务通常通过一个名为 VCAP_SERVICES 的特殊环境变量暴露。
在配置绑定器连接时,您可以使用环境变量中的值,如 dataflow Cloud Foundry Server 文档中所述。
绑定器实现
以下是可用绑定器实现的列表
如前所述,绑定器抽象也是框架的扩展点之一。因此,如果您在上述列表中找不到合适的绑定器,您可以在 Spring Cloud Stream 之上实现自己的绑定器。在《如何从零开始创建 Spring Cloud Stream Binder》一文中,一位社区成员详细记录了实现自定义绑定器所需的步骤,并提供了示例。这些步骤也在实现自定义绑定器部分中突出显示。