3.0.13.RELEASE
参考指南
本指南介绍了 Spring Cloud Stream 绑定器的 Apache Kafka 实现。它包含有关其设计、用法和配置选项的信息,以及 Spring Cloud Stream 概念如何映射到 Apache Kafka 特定构造的信息。此外,本指南还解释了 Spring Cloud Stream 的 Kafka Streams 绑定能力。
1. Apache Kafka 绑定器
1.1. 用法
要使用 Apache Kafka 绑定器,您需要将 spring-cloud-stream-binder-kafka 添加为 Spring Cloud Stream 应用程序的依赖项,如以下 Maven 示例所示
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>或者,您也可以使用 Spring Cloud Stream Kafka Starter,如以下 Maven 示例所示
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>1.2. 概述
下图显示了 Apache Kafka 绑定器如何工作的简化图
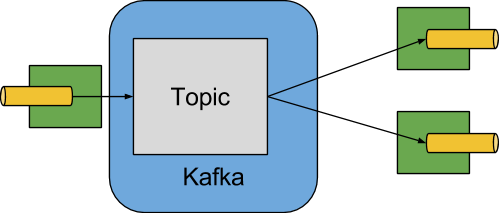
Apache Kafka 绑定器实现将每个目标映射到一个 Apache Kafka 主题。消费者组直接映射到相同的 Apache Kafka 概念。分区也直接映射到 Apache Kafka 分区。
绑定器目前使用 Apache Kafka kafka-clients 2.3.1 版本。此客户端可以与较旧的 broker 通信(参见 Kafka 文档),但某些功能可能不可用。例如,对于早于 0.11.x.x 的版本,不支持原生 header。此外,0.11.x.x 不支持 autoAddPartitions 属性。
1.3. 配置选项
本节包含 Apache Kafka 绑定器使用的配置选项。
有关绑定器的常用配置选项和属性,请参阅核心文档中的绑定属性。
1.3.1. Kafka 绑定器属性
- spring.cloud.stream.kafka.binder.brokers
-
Kafka 绑定器连接的 broker 列表。
默认值:
localhost。 - spring.cloud.stream.kafka.binder.defaultBrokerPort
-
brokers允许指定包含或不包含端口信息的主机(例如host1,host2:port2)。当 broker 列表中未配置端口时,此属性设置默认端口。默认值:
9092。 - spring.cloud.stream.kafka.binder.configuration
-
传递给绑定器创建的所有客户端(包括生产者和消费者)的客户端属性的 Key/Value map。由于这些属性同时用于生产者和消费者,因此用法应限于通用属性,例如安全设置。通过此配置提供的未知 Kafka 生产者或消费者属性会被过滤掉,不允许传播。此处的属性会覆盖在 Spring Boot 中设置的任何属性。
默认值:空 map。
- spring.cloud.stream.kafka.binder.consumerProperties
-
任意 Kafka 客户端消费者属性的 Key/Value map。除了支持已知的 Kafka 消费者属性外,此处也允许未知消费者属性。此处的属性会覆盖在 Spring Boot 中设置的任何属性以及上面
configuration属性中设置的属性。默认值:空 map。
- spring.cloud.stream.kafka.binder.headers
-
由绑定器传输的自定义 header 列表。仅在使用
kafka-clients版本 < 0.11.0.0 与旧应用程序 (⇐ 1.3.x) 通信时需要。更新版本原生支持 header。默认值:空。
- spring.cloud.stream.kafka.binder.healthTimeout
-
等待获取分区信息的时间,单位为秒。如果此计时器过期,则健康状态报告为 down。
默认值:10。
- spring.cloud.stream.kafka.binder.requiredAcks
-
broker 上所需的 ack 数量。请参阅 Kafka 文档中的生产者
acks属性。默认值:
1。 - spring.cloud.stream.kafka.binder.minPartitionCount
-
仅当设置了
autoCreateTopics或autoAddPartitions时有效。绑定器在其生产或消费数据的 topic 上配置的全局最小分区数。它可能被生产者的partitionCount设置或生产者的instanceCount * concurrency设置的值所覆盖(如果两者中的任何一个更大)。默认值:
1。 - spring.cloud.stream.kafka.binder.producerProperties
-
任意 Kafka 客户端生产者属性的 Key/Value map。除了支持已知的 Kafka 生产者属性外,此处也允许未知生产者属性。此处的属性会覆盖在 Spring Boot 中设置的任何属性以及上面
configuration属性中设置的属性。默认值:空 map。
- spring.cloud.stream.kafka.binder.replicationFactor
-
如果
autoCreateTopics处于活动状态,则自动创建主题的副本因子。可以在每个绑定上覆盖。如果您使用的是早于 2.4 的 Kafka broker 版本,则此值应至少设置为 1。从 3.0.8 版本开始,绑定器使用−1作为默认值,这表示将使用 broker 的 'default.replication.factor' 属性来确定副本数量。请咨询您的 Kafka broker 管理员,了解是否有要求最小副本因子的策略,如果存在,则通常default.replication.factor将与该值匹配,并且应使用−1,除非您需要大于最小值的副本因子。默认值:
−1。 - spring.cloud.stream.kafka.binder.autoCreateTopics
-
如果设置为
true,绑定器会自动创建新主题。如果设置为false,绑定器则依赖于已经配置好的主题。在后一种情况下,如果主题不存在,绑定器将无法启动。此设置独立于 broker 的 auto.create.topics.enable设置,并且不受其影响。如果服务器设置为自动创建主题,则它们可能会作为元数据检索请求的一部分被创建,并使用默认的 broker 设置。默认值:
true。 - spring.cloud.stream.kafka.binder.autoAddPartitions
-
如果设置为
true,绑定器在需要时创建新分区。如果设置为false,绑定器则依赖于已经配置好的主题分区大小。如果目标主题的分区计数小于预期值,绑定器将无法启动。默认值:
false。 - spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix
-
在绑定器中启用事务。请参阅 Kafka 文档中的
transaction.id以及 `spring-kafka` 文档中的事务。启用事务后,单个producer属性将被忽略,所有生产者都使用spring.cloud.stream.kafka.binder.transaction.producer.*属性。默认值
null(无事务) - spring.cloud.stream.kafka.binder.transaction.producer.*
-
事务绑定器中生产者的全局生产者属性。请参阅
spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix和Kafka 生产者属性以及所有绑定器支持的通用生产者属性。默认值:参见单独的生产者属性。
- spring.cloud.stream.kafka.binder.headerMapperBeanName
-
用于将
spring-messagingheader 映射到 Kafka header 以及从 Kafka header 映射回来的KafkaHeaderMapperbean 的名称。例如,如果您希望在使用 JSON 反序列化 header 的BinderHeaderMapperbean 中自定义受信任的包,则可以使用此属性。如果未通过此属性将此自定义BinderHeaderMapperbean 提供给绑定器,则绑定器会查找名称为kafkaBinderHeaderMapper且类型为BinderHeaderMapper的 header mapper bean,然后才会回退到绑定器创建的默认BinderHeaderMapper。默认值:无。
- spring.cloud.stream.kafka.binder.considerDownWhenAnyPartitionHasNoLeader
-
用于在主题上的任何分区(无论哪个消费者正在从中接收数据)被发现没有 leader 时,将绑定器健康状态设置为
down的标志。默认值:
false。 - spring.cloud.stream.kafka.binder.certificateStoreDirectory
-
当 truststore 或 keystore 证书位置以 classpath URL (`classpath:…`) 形式给出时,绑定器会将 JAR 文件内部 classpath 位置的资源复制到文件系统上的位置。文件将被移动到此属性指定的值所对应的位置,该位置必须是文件系统上存在且运行应用程序的进程可写的目录。如果未设置此值且证书文件是 classpath 资源,则会将其移动到 `System.getProperty("java.io.tmpdir")` 返回的系统临时目录。如果此值存在但文件系统上找不到该目录或不可写,情况也同样如此。
默认值:无。
1.3.2. Kafka 消费者属性
为避免重复,Spring Cloud Stream 支持为所有通道设置值,格式为 spring.cloud.stream.kafka.default.consumer.<property>=<value>。 |
以下属性仅适用于 Kafka 消费者,并且必须以 spring.cloud.stream.kafka.bindings.<channelName>.consumer. 为前缀。
- admin.configuration
-
自 2.1.1 版本起,此属性已弃用,推荐使用
topic.properties,未来版本将移除对其的支持。 - admin.replicas-assignment
-
自 2.1.1 版本起,此属性已弃用,推荐使用
topic.replicas-assignment,未来版本将移除对其的支持。 - admin.replication-factor
-
自 2.1.1 版本起,此属性已弃用,推荐使用
topic.replication-factor,未来版本将移除对其的支持。 - autoRebalanceEnabled
-
当设置为
true时,主题分区会在消费者组的成员之间自动重新平衡。当设置为false时,每个消费者会根据spring.cloud.stream.instanceCount和spring.cloud.stream.instanceIndex分配固定的分区集合。这要求在每个启动的实例上适当地设置spring.cloud.stream.instanceCount和spring.cloud.stream.instanceIndex属性。在这种情况下,spring.cloud.stream.instanceCount属性的值通常必须大于 1。默认值:
true。 - ackEachRecord
-
当
autoCommitOffset为true时,此设置决定是否在处理完每条记录后提交偏移量。默认情况下,偏移量会在处理完consumer.poll()返回的批次中的所有记录后提交。poll 返回的记录数量可以通过 Kafka 属性max.poll.records控制,该属性通过消费者configuration属性设置。将其设置为true可能会导致性能下降,但这样做可以减少发生故障时记录被重复投递的可能性。此外,请参阅绑定器requiredAcks属性,它也会影响提交偏移量的性能。默认值:
false。 - autoCommitOffset
-
消息处理完成后是否自动提交偏移量。如果设置为
false,则入站消息中会包含一个键为kafka_acknowledgment、类型为org.springframework.kafka.support.Acknowledgment的 header。应用程序可以使用此 header 来确认消息。详细信息请参见示例部分。当此属性设置为false时,Kafka 绑定器将确认模式设置为org.springframework.kafka.listener.AbstractMessageListenerContainer.AckMode.MANUAL,并且应用程序负责确认记录。另请参阅ackEachRecord。默认值:
true。 - autoCommitOnError
-
仅当
autoCommitOffset设置为true时有效。如果设置为 `false`,则抑制导致错误的消息的自动提交,仅对成功处理的消息进行提交。在发生持久性故障时,它允许流从最后一次成功处理的消息自动重播。如果设置为 `true`,则始终自动提交(如果启用了自动提交)。如果未设置(默认值),则其效果与 `enableDlq` 相同,如果错误消息发送到 DLQ 则自动提交,否则不提交。默认值:未设置。
- resetOffsets
-
是否将消费者的偏移量重置为
startOffset提供的值。如果提供了KafkaRebalanceListener,则必须为 false;参见使用 KafkaRebalanceListener。默认值:
false。 - startOffset
-
新组的起始偏移量。允许的值:
earliest和latest。如果消费者组通过spring.cloud.stream.bindings.<channelName>.group为消费者 'binding' 明确设置,则 'startOffset' 设置为earliest。否则,对于anonymous消费者组,它设置为latest。另请参阅resetOffsets(此列表前面)。默认值:null (等同于
earliest)。 - enableDlq
-
设置为 true 时,为消费者启用 DLQ 行为。默认情况下,导致错误的消息会被转发到名为
error.<destination>.<group>的主题。可以通过设置dlqName属性或定义类型为DlqDestinationResolver的@Bean来配置 DLQ 主题名称。这为常见的 Kafka 重播场景提供了一种替代方案,适用于错误数量相对较少且重播整个原始主题可能过于繁琐的情况。有关详细信息,请参见死信主题处理。从 2.0 版本开始,发送到 DLQ 主题的消息会增强以下 header:x-original-topic、x-exception-message和x-exception-stacktrace,类型为byte[]。默认情况下,失败的记录会发送到 DLQ 主题中与原始记录相同分区号的分区。有关如何更改此行为,请参见死信主题分区选择。当destinationIsPattern为true时不允许使用此属性。默认值:
false。 - dlqPartitions
-
当
enableDlq为 true 且未设置此属性时,会创建一个与主主题具有相同分区数的死信主题。通常,死信记录会发送到死信主题中与原始记录相同分区号的分区。此行为可以更改;参见死信主题分区选择。如果此属性设置为1且没有DqlPartitionFunctionbean,所有死信记录将写入分区0。如果此属性大于1,您必须提供一个DlqPartitionFunctionbean。请注意,实际的分区计数受绑定器minPartitionCount属性的影响。默认值:
none - configuration
-
包含通用 Kafka 消费者属性的 key/value 对的 Map。除了 Kafka 消费者属性外,还可以在此处传递其他配置属性。例如,应用程序所需的一些属性,如
spring.cloud.stream.kafka.bindings.input.consumer.configuration.foo=bar。默认值:空 map。
- dlqName
-
接收错误消息的 DLQ 主题名称。
默认值:null(如果未指定,导致错误的消息将转发到名为
error.<destination>.<group>的主题)。 - dlqProducerProperties
-
通过此属性可以设置 DLQ 特定的生产者属性。所有通过 Kafka 生产者属性可用的属性都可以通过此属性设置。当消费者启用原生解码(即 useNativeDecoding: true)时,应用程序必须为 DLQ 提供相应的 key/value 序列化器。这必须以
dlqProducerProperties.configuration.key.serializer和dlqProducerProperties.configuration.value.serializer的形式提供。默认值:默认 Kafka 生产者属性。
- standardHeaders
-
指示入站通道适配器填充哪些标准 header。允许的值:
none、id、timestamp或both。如果使用原生反序列化并且第一个接收消息的组件需要id(例如配置为使用 JDBC 消息存储的聚合器),则此属性非常有用。默认值:
none - converterBeanName
-
实现
RecordMessageConverter的 bean 的名称。在入站通道适配器中使用,以替换默认的MessagingMessageConverter。默认值:
null - idleEventInterval
-
表示最近没有收到消息的事件之间的间隔,单位为毫秒。使用
ApplicationListener<ListenerContainerIdleEvent>来接收这些事件。使用示例请参见示例:暂停和恢复消费者。默认值:
30000 - destinationIsPattern
-
当为 true 时,目标被视为由 broker 用于匹配主题名称的正则表达式
Pattern。当为 true 时,不会预置主题,并且不允许使用enableDlq,因为绑定器在预置阶段不知道主题名称。请注意,检测匹配模式的新主题所需的时间由消费者属性metadata.max.age.ms控制,该属性(在编写本文时)默认为 300,000ms(5 分钟)。这可以通过上面configuration属性进行配置。默认值:
false - topic.properties
-
预置新主题时使用的 Kafka 主题属性的
Map。例如 `spring.cloud.stream.kafka.bindings.input.consumer.topic.properties.message.format.version=0.9.0.0`默认值:无。
- topic.replicas-assignment
-
副本分配的 Map<Integer, List<Integer>>,其中 key 是分区,value 是分配。预置新主题时使用。参见
kafka-clientsjar 中的NewTopicJavadoc。默认值:无。
- topic.replication-factor
-
预置主题时使用的副本因子。覆盖绑定器范围的设置。如果存在
replicas-assignments则忽略。默认值:none(使用绑定器范围的默认值 -1)。
- pollTimeout
-
在可轮询消费者中进行轮询使用的超时时间。
默认值:5 秒。
- transactionManager
-
用于覆盖此绑定器的事务管理器的
KafkaAwareTransactionManagerbean 名称。通常,如果您想使用ChainedKafkaTransactionManaager将另一个事务与 Kafka 事务同步,则需要此设置。为了实现记录的精确一次消费和生产,消费者和生产者绑定必须都配置相同的事务管理器。默认值:无。
- txCommitRecovered
-
使用事务绑定器时,默认情况下,恢复的记录(例如,当重试耗尽且记录被发送到死信主题时)的偏移量将通过新的事务提交。将此属性设置为
false会抑制提交恢复记录的偏移量。默认值:true。
1.3.3. 重置偏移量
应用程序启动时,每个分配的分区的初始位置取决于 startOffset 和 resetOffsets 这两个属性。如果 resetOffsets 为 false,则应用正常的 Kafka 消费者 auto.offset.reset 语义。即,如果某个分区的绑定消费者组没有已提交的偏移量,则位置为 earliest 或 latest。默认情况下,具有显式 group 的绑定使用 earliest,而匿名绑定(没有 group)使用 latest。这些默认值可以通过设置 startOffset 绑定属性来覆盖。绑定首次使用特定 group 启动时,将没有已提交的偏移量。没有已提交偏移量的另一种情况是偏移量已过期。对于现代 broker(自 2.1 版本起)以及默认的 broker 属性,偏移量在最后一个成员离开组后 7 天过期。有关详细信息,请参阅 offsets.retention.minutes broker 属性。
当 resetOffsets 为 true 时,绑定器应用与 broker 上没有已提交偏移量时类似的语义,就好像此绑定从未消费过该主题一样;即忽略任何当前的已提交偏移量。
以下是可能使用此属性的两个用例。
-
消费包含 key/value 对的压缩主题。将
resetOffsets设置为true,将startOffset设置为earliest;绑定将对所有新分配的分区执行seekToBeginning操作。 -
消费包含事件的主题,您只对该绑定运行时发生的事件感兴趣。将
resetOffsets设置为true,将startOffset设置为latest;绑定将对所有新分配的分区执行seekToEnd操作。
| 如果在初始分配后发生重新平衡,seek 操作将仅对初始分配期间未分配的新分配分区执行。 |
有关主题偏移量的更多控制,请参见使用 KafkaRebalanceListener;当提供了 listener 时,resetOffsets 不应设置为 true,否则会导致错误。 >>>>>>> 7bc90c10… GH-1084: 添加 txCommitRecovered 属性
1.3.4. 消费批次
从 3.0 版本开始,当 spring.cloud.stream.binding.<name>.consumer.batch-mode 设置为 true 时,通过轮询 Kafka Consumer 收到的所有记录将以 List<?> 的形式呈现给 listener 方法。否则,方法将一次处理一条记录。批次的大小由 Kafka 消费者属性 max.poll.records、fetch.min.bytes、fetch.max.wait.ms 控制;有关详细信息,请参阅 Kafka 文档。
请注意,@StreamListener 不支持批处理模式 - 它只适用于较新的函数式编程模型。
使用批处理模式时,不支持绑定器内的重试,因此 maxAttempts 将被覆盖为 1。您可以配置 SeekToCurrentBatchErrorHandler(使用 ListenerContainerCustomizer)以实现与绑定器内重试类似的功能。您还可以使用手动 AckMode 并调用 Ackowledgment.nack(index, sleep) 来提交部分批次的偏移量,并重新投递剩余的记录。有关这些技术的更多信息,请参阅 Spring for Apache Kafka 文档。 |
1.3.5. Kafka 生产者属性
为避免重复,Spring Cloud Stream 支持为所有通道设置值,格式为 spring.cloud.stream.kafka.default.producer.<property>=<value>。 |
以下属性仅适用于 Kafka 生产者,并且必须以 spring.cloud.stream.kafka.bindings.<channelName>.producer. 为前缀。
- admin.configuration
-
自 2.1.1 版本起,此属性已弃用,推荐使用
topic.properties,未来版本将移除对其的支持。 - admin.replicas-assignment
-
自 2.1.1 版本起,此属性已弃用,推荐使用
topic.replicas-assignment,未来版本将移除对其的支持。 - admin.replication-factor
-
自 2.1.1 版本起,此属性已弃用,推荐使用
topic.replication-factor,未来版本将移除对其的支持。 - bufferSize
-
Kafka 生产者在发送前尝试批量处理的数据的上限,单位为字节。
默认值:
16384。 - sync
-
生产者是否同步。
默认值:
false。 - sendTimeoutExpression
-
一个针对出站消息评估的 SpEL 表达式,用于在启用同步发布时评估等待 ack 的时间——例如
headers['mySendTimeout']。超时值以毫秒为单位。在 3.0 版本之前,除非使用原生编码,否则无法使用 payload,因为在评估此表达式时,payload 已经是以byte[]的形式存在。现在,表达式在 payload 转换之前进行评估。默认值:
none。 - batchTimeout
-
生产者等待更多消息在同一批次中累积后才发送消息的时间长度。(通常,生产者根本不等待,只发送前一次发送进行中累积的所有消息。)非零值可能会以延迟为代价提高吞吐量。
默认值:
0。 - messageKeyExpression
-
一个针对出站消息评估的 SpEL 表达式,用于填充生产的 Kafka 消息的 key——例如
headers['myKey']。在 3.0 版本之前,除非使用原生编码,否则无法使用 payload,因为在评估此表达式时,payload 已经是以byte[]的形式存在。现在,表达式在 payload 转换之前进行评估。对于常规处理器(`Function默认值:
none。 - headerPatterns
-
一个逗号分隔的简单模式列表,用于匹配要映射到
ProducerRecord中的 KafkaHeaders的 Spring messaging header。模式可以以通配符(星号)开头或结尾。模式可以通过前缀!进行否定。匹配在第一次匹配(肯定或否定)后停止。例如,!ask,as*将通过ash但不通过ask。id和timestamp永远不会映射。默认值:
*(所有 header - 除了id和timestamp) - configuration
-
包含通用 Kafka 生产者属性的 key/value 对的 Map。
默认值:空 map。
- topic.properties
-
预置新主题时使用的 Kafka 主题属性的
Map。例如 `spring.cloud.stream.kafka.bindings.output.producer.topic.properties.message.format.version=0.9.0.0` - topic.replicas-assignment
-
副本分配的 Map<Integer, List<Integer>>,其中 key 是分区,value 是分配。预置新主题时使用。参见
kafka-clientsjar 中的NewTopicJavadoc。默认值:无。
- topic.replication-factor
-
预置主题时使用的副本因子。覆盖绑定器范围的设置。如果存在
replicas-assignments则忽略。默认值:none(使用绑定器范围的默认值 -1)。
- useTopicHeader
-
设置为
true,以使用出站消息中KafkaHeaders.TOPIC消息 header 的值覆盖默认的绑定目标(主题名称)。如果 header 不存在,则使用默认的绑定目标。默认值:false。 - recordMetadataChannel
-
成功发送结果应发送到的
MessageChannel的 bean 名称;该 bean 必须存在于应用程序上下文中。发送到通道的消息是发送的消息(如果进行了转换),并带有附加的 headerKafkaHeaders.RECORD_METADATA。该 header 包含由 Kafka 客户端提供的RecordMetadata对象;它包含记录在主题中写入的分区和偏移量。
ResultMetadata meta = sendResultMsg.getHeaders().get(KafkaHeaders.RECORD_METADATA, RecordMetadata.class)
失败的发送会发送到生产者错误通道(如果已配置);参见错误通道。默认值:null
+
Kafka 绑定器使用生产者的 partitionCount 设置作为创建具有给定分区计数的主题的提示(结合 minPartitionCount,取两者中的最大值)。配置绑定器的 minPartitionCount 和应用程序的 partitionCount 时请谨慎,因为会使用较大的值。如果主题已经存在但分区计数较少且 autoAddPartitions 被禁用(默认),绑定器将无法启动。如果主题已经存在但分区计数较少且 autoAddPartitions 被启用,则会添加新分区。如果主题已经存在但分区数大于(minPartitionCount 或 partitionCount)的最大值,则使用现有分区计数。 |
- compression
-
设置
compression.type生产者属性。支持的值有none、gzip、snappy和lz4。如果您按照 Spring for Apache Kafka 文档中所述覆盖kafka-clientsjar 至 2.1.0(或更高版本),并希望使用zstd压缩,请使用 `spring.cloud.stream.kafka.bindings.<binding-name>.producer.configuration.compression.type=zstd`。默认值:
none。 - closeTimeout
-
关闭生产者时等待的超时时间,单位为秒。
默认值:
30
1.3.6. 使用示例
本节中,我们将展示前述属性在特定场景下的使用。
示例:将 autoCommitOffset 设置为 false 并依赖手动确认
此示例说明了如何在消费者应用程序中手动确认偏移量。
此示例要求将 spring.cloud.stream.kafka.bindings.input.consumer.autoCommitOffset 设置为 false。请使用您示例中对应的输入通道名称。
@SpringBootApplication
@EnableBinding(Sink.class)
public class ManuallyAcknowdledgingConsumer {
public static void main(String[] args) {
SpringApplication.run(ManuallyAcknowdledgingConsumer.class, args);
}
@StreamListener(Sink.INPUT)
public void process(Message<?> message) {
Acknowledgment acknowledgment = message.getHeaders().get(KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class);
if (acknowledgment != null) {
System.out.println("Acknowledgment provided");
acknowledgment.acknowledge();
}
}
}示例:安全配置
Apache Kafka 0.9 支持客户端和 broker 之间的安全连接。要利用此功能,请遵循 Apache Kafka 文档中的指南以及 Kafka 0.9 Confluent 文档中的安全指南。使用 spring.cloud.stream.kafka.binder.configuration 选项为绑定器创建的所有客户端设置安全属性。
例如,要将 security.protocol 设置为 SASL_SSL,请设置以下属性
spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_SSL所有其他安全属性都可以用类似的方式设置。
使用 Kerberos 时,请按照参考文档中的说明创建和引用 JAAS 配置。
Spring Cloud Stream 支持通过使用 JAAS 配置文件和 Spring Boot 属性将 JAAS 配置信息传递给应用程序。
使用 JAAS 配置文件
可以使用系统属性为 Spring Cloud Stream 应用程序设置 JAAS 和(可选)krb5 文件位置。以下示例显示了如何使用 JAAS 配置文件启动具有 SASL 和 Kerberos 的 Spring Cloud Stream 应用程序
java -Djava.security.auth.login.config=/path.to/kafka_client_jaas.conf -jar log.jar \
--spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT使用 Spring Boot 属性
作为 JAAS 配置文件的替代方案,Spring Cloud Stream 提供了一种机制,允许使用 Spring Boot 属性为 Spring Cloud Stream 应用程序设置 JAAS 配置。
以下属性可用于配置 Kafka 客户端的登录上下文
- spring.cloud.stream.kafka.binder.jaas.loginModule
-
登录模块名称。通常情况下无需设置。
默认值:
com.sun.security.auth.module.Krb5LoginModule。 - spring.cloud.stream.kafka.binder.jaas.controlFlag
-
登录模块的控制标志。
默认值:
required。 - spring.cloud.stream.kafka.binder.jaas.options
-
包含登录模块选项的 key/value 对的 Map。
默认值:空 map。
以下示例显示了如何使用 Spring Boot 配置属性启动具有 SASL 和 Kerberos 的 Spring Cloud Stream 应用程序
java --spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.autoCreateTopics=false \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT \
--spring.cloud.stream.kafka.binder.jaas.options.useKeyTab=true \
--spring.cloud.stream.kafka.binder.jaas.options.storeKey=true \
--spring.cloud.stream.kafka.binder.jaas.options.keyTab=/etc/security/keytabs/kafka_client.keytab \
--spring.cloud.stream.kafka.binder.jaas.options.principal=kafka-client-1@EXAMPLE.COM前面的示例等同于以下 JAAS 文件
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/security/keytabs/kafka_client.keytab"
principal="[email protected]";
};如果所需的主题已存在于 broker 上或将由管理员创建,则可以关闭自动创建,并且只需发送客户端 JAAS 属性。
请勿在同一应用程序中混用 JAAS 配置文件和 Spring Boot 属性。如果已存在 -Djava.security.auth.login.config 系统属性,Spring Cloud Stream 将忽略 Spring Boot 属性。 |
在 Kerberos 环境下使用 autoCreateTopics 和 autoAddPartitions 时请注意。通常,应用程序使用的 principals 可能在 Kafka 和 Zookeeper 中没有管理权限。因此,依赖 Spring Cloud Stream 创建/修改主题可能会失败。在安全环境中,我们强烈建议使用 Kafka 工具以管理方式创建主题和管理 ACL。 |
示例:暂停和恢复消费者
如果你想暂停消费但不引起分区再平衡,可以暂停和恢复消费者。这可以通过将 Consumer 作为参数添加到你的 @StreamListener 中来实现。要恢复,你需要一个针对 ListenerContainerIdleEvent 实例的 ApplicationListener。事件发布频率由 idleEventInterval 属性控制。由于消费者不是线程安全的,你必须在调用线程上调用这些方法。
下面的简单应用程序展示了如何暂停和恢复
@SpringBootApplication
@EnableBinding(Sink.class)
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@StreamListener(Sink.INPUT)
public void in(String in, @Header(KafkaHeaders.CONSUMER) Consumer<?, ?> consumer) {
System.out.println(in);
consumer.pause(Collections.singleton(new TopicPartition("myTopic", 0)));
}
@Bean
public ApplicationListener<ListenerContainerIdleEvent> idleListener() {
return event -> {
System.out.println(event);
if (event.getConsumer().paused().size() > 0) {
event.getConsumer().resume(event.getConsumer().paused());
}
};
}
}1.4. 事务绑定器
通过将 spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix 设置为非空值(例如 tx-)来启用事务。在 processor 应用程序中使用时,消费者启动事务;在消费者线程上发送的任何记录都会参与同一事务。当监听器正常退出时,监听器容器会将偏移量发送到事务并提交。使用一个通用的 producer factory 来配置所有 producer 绑定,这些绑定使用 spring.cloud.stream.kafka.binder.transaction.producer.* 属性进行配置;单个绑定的 Kafka producer 属性将被忽略。
常规的 binder 重试(和死信处理)在事务中不受支持,因为重试将在原始事务中运行,该事务可能会回滚,并且发布的任何记录也将回滚。当启用重试时(通用属性 maxAttempts 大于零),重试属性用于配置一个 DefaultAfterRollbackProcessor 以在容器级别启用重试。类似地,死信记录的发布功能不是在事务内完成,而是移至监听器容器,同样通过在主事务回滚后运行的 DefaultAfterRollbackProcessor 来实现。 |
如果你想在 source 应用程序中使用事务,或者从某个任意线程进行仅 producer 的事务(例如 @Scheduled 方法),你必须获取事务性 producer factory 的引用,并使用它定义一个 KafkaTransactionManager bean。
@Bean
public PlatformTransactionManager transactionManager(BinderFactory binders) {
ProducerFactory<byte[], byte[]> pf = ((KafkaMessageChannelBinder) binders.getBinder(null,
MessageChannel.class)).getTransactionalProducerFactory();
return new KafkaTransactionManager<>(pf);
}请注意,我们使用 BinderFactory 获取 binder 的引用;当只配置了一个 binder 时,在第一个参数中使用 null。如果配置了多个 binder,使用 binder 名称来获取引用。一旦我们获得了 binder 的引用,就可以获取 ProducerFactory 的引用并创建一个事务管理器。
然后你就可以使用正常的 Spring 事务支持,例如 TransactionTemplate 或 @Transactional,例如
public static class Sender {
@Transactional
public void doInTransaction(MessageChannel output, List<String> stuffToSend) {
stuffToSend.forEach(stuff -> output.send(new GenericMessage<>(stuff)));
}
}如果你想将仅 producer 的事务与来自其他事务管理器的事务同步,请使用 ChainedTransactionManager。
1.5. 错误通道
从 1.3 版本开始,binder 无条件地将每个消费者目标地的异常发送到错误通道,也可以配置将异步 producer 发送失败发送到错误通道。更多信息请参阅错误处理这一节。
发送失败的 ErrorMessage 的 payload 是一个 KafkaSendFailureException,包含以下属性
-
failedMessage: 未能发送的 Spring MessagingMessage<?>。 -
record: 由failedMessage创建的原始ProducerRecord
没有自动处理 producer 异常(例如发送到死信队列)。你可以使用自己的 Spring Integration 流来消费这些异常。
1.6. Kafka 指标
Kafka binder 模块公开了以下指标
spring.cloud.stream.binder.kafka.offset: 此指标指示给定消费者组从给定 binder 的主题尚未消费的消息数量。提供的指标基于 Micrometer 库。如果 classpath 中存在 Micrometer 且应用程序未提供其他此类 bean,则 binder 会创建 KafkaBinderMetrics bean。该指标包含消费者组信息、主题以及与主题最新偏移量相比的已提交偏移量的实际滞后量。此指标对于向 PaaS 平台提供自动伸缩反馈特别有用。
通过在应用程序中提供以下组件,可以阻止 KafkaBinderMetrics 创建必要的消费者等基础设施并报告指标。
@Component
class NoOpBindingMeters {
NoOpBindingMeters(MeterRegistry registry) {
registry.config().meterFilter(
MeterFilter.denyNameStartsWith(KafkaBinderMetrics.OFFSET_LAG_METRIC_NAME));
}
}有关如何选择性抑制 meter 的更多详细信息,请参阅此处。
1.7. Tombstone Records (null 记录值)
使用 compacted topic 时,值为 null 的记录(也称为 tombstone 记录)表示删除键。要在 @StreamListener 方法中接收此类消息,参数必须标记为非必需,以便接收 null 值参数。
@StreamListener(Sink.INPUT)
public void in(@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) byte[] key,
@Payload(required = false) Customer customer) {
// customer is null if a tombstone record
...
}1.8. 使用 KafkaRebalanceListener
应用程序可能希望在分区最初分配时,将主题/分区 seek 到任意偏移量,或对消费者执行其他操作。从 2.1 版本开始,如果在应用程序上下文中提供一个单独的 KafkaRebalanceListener bean,它将被注入到所有 Kafka 消费者绑定中。
public interface KafkaBindingRebalanceListener {
/**
* Invoked by the container before any pending offsets are committed.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
*/
default void onPartitionsRevokedBeforeCommit(String bindingName, Consumer<?, ?> consumer,
Collection<TopicPartition> partitions) {
}
/**
* Invoked by the container after any pending offsets are committed.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
*/
default void onPartitionsRevokedAfterCommit(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
}
/**
* Invoked when partitions are initially assigned or after a rebalance.
* Applications might only want to perform seek operations on an initial assignment.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
* @param initial true if this is the initial assignment.
*/
default void onPartitionsAssigned(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions,
boolean initial) {
}
}提供 rebalance listener 时,不能将 resetOffsets 消费者属性设置为 true。
1.9. 自定义消费者和生产者配置
如果你想对用于在 Kafka 中创建 ConsumerFactory 和 ProducerFactory 的消费者和 producer 配置进行高级定制,可以实现以下 customizer。
-
ConsumerConfigCustomizer
-
ProducerConfigCustomizer
这两个接口都提供了一种配置用于消费者和 producer 属性的配置映射的方式。例如,如果你想访问在应用程序级别定义的 bean,可以在 configure 方法的实现中注入它。当 binder 检测到这些 customizer 可用作 bean 时,它将在创建消费者和 producer factory 之前立即调用 configure 方法。
1.10. 自定义 AdminClient 配置
与上面的消费者和 producer 配置定制类似,应用程序也可以通过提供一个 AdminClientConfigCustomizer 来定制 Admin 客户端的配置。AdminClientConfigCustomizer 的 configure 方法提供了对 Admin 客户端属性的访问,你可以使用它来定义进一步的定制。Binder 的 Kafka 主题 provisioner 对通过此 customizer 提供的属性赋予最高优先级。这里是一个提供此 customizer bean 的示例。
@Bean
public AdminClientConfigCustomizer adminClientConfigCustomizer() {
return props -> {
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SASL_SSL");
};
}1.11. 死信主题处理
1.11.1. 死信主题分区选择
默认情况下,记录使用与原始记录相同的分区发布到死信主题。这意味着死信主题必须至少拥有与原始记录相同数量的分区。
要更改此行为,请将 DlqPartitionFunction 实现作为 @Bean 添加到应用程序上下文中。只能存在一个此类 bean。该函数会接收消费者组、失败的 ConsumerRecord 和异常。例如,如果你总是想路由到分区 0,你可以使用
@Bean
public DlqPartitionFunction partitionFunction() {
return (group, record, ex) -> 0;
}如果你将消费者绑定的 dlqPartitions 属性设置为 1(并且 binder 的 minPartitionCount 等于 1),则无需提供 DlqPartitionFunction;框架将始终使用分区 0。如果你将消费者绑定的 dlqPartitions 属性设置为大于 1 的值(或 binder 的 minPartitionCount 大于 1),则**必须**提供 DlqPartitionFunction bean,即使分区数量与原始主题相同。 |
也可以为 DLQ 主题定义自定义名称。为此,请将 DlqDestinationResolver 的实现作为 @Bean 创建到应用程序上下文中。当 binder 检测到此类 bean 时,它会优先使用,否则将使用 dlqName 属性。如果两者都找不到,它将默认为 error.<destination>.<group>。这里是一个将 DlqDestinationResolver 作为 @Bean 的示例。
@Bean
public DlqDestinationResolver dlqDestinationResolver() {
return (rec, ex) -> {
if (rec.topic().equals("word1")) {
return "topic1-dlq";
}
else {
return "topic2-dlq";
}
};
}提供 DlqDestinationResolver 的实现时,要记住一个重要的事情是,binder 中的 provisioner 不会自动为应用程序创建主题。这是因为 binder 无法推断出实现可能发送到的所有 DLQ 主题的名称。因此,如果你使用此策略提供 DLQ 名称,确保这些主题事先创建是应用程序的责任。
1.11.2. 处理死信主题中的记录
由于框架无法预料用户希望如何处理死信消息,因此它不提供任何标准机制来处理它们。如果死信的原因是临时的,你可能希望将消息路由回原始主题。但是,如果问题是永久性的,可能会导致无限循环。本主题中的示例 Spring Boot 应用程序展示了如何将这些消息路由回原始主题,但在三次尝试后将其移动到“停车场”主题。该应用程序是另一个 spring-cloud-stream 应用程序,它从死信主题读取。当 5 秒内没有收到消息时,它会终止。
示例假设原始目的地是 so8400out,消费者组是 so8400。
有几种策略可以考虑
-
考虑仅在主应用程序未运行时运行重新路由。否则,临时错误的重试次数会很快用完。
-
或者,使用两阶段方法:使用此应用程序路由到一个第三主题,然后使用另一个应用程序从该主题路由回主主题。
以下代码清单显示了示例应用程序
spring.cloud.stream.bindings.input.group=so8400replay
spring.cloud.stream.bindings.input.destination=error.so8400out.so8400
spring.cloud.stream.bindings.output.destination=so8400out
spring.cloud.stream.bindings.parkingLot.destination=so8400in.parkingLot
spring.cloud.stream.kafka.binder.configuration.auto.offset.reset=earliest
spring.cloud.stream.kafka.binder.headers=x-retries@SpringBootApplication
@EnableBinding(TwoOutputProcessor.class)
public class ReRouteDlqKApplication implements CommandLineRunner {
private static final String X_RETRIES_HEADER = "x-retries";
public static void main(String[] args) {
SpringApplication.run(ReRouteDlqKApplication.class, args).close();
}
private final AtomicInteger processed = new AtomicInteger();
@Autowired
private MessageChannel parkingLot;
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public Message<?> reRoute(Message<?> failed) {
processed.incrementAndGet();
Integer retries = failed.getHeaders().get(X_RETRIES_HEADER, Integer.class);
if (retries == null) {
System.out.println("First retry for " + failed);
return MessageBuilder.fromMessage(failed)
.setHeader(X_RETRIES_HEADER, new Integer(1))
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build();
}
else if (retries.intValue() < 3) {
System.out.println("Another retry for " + failed);
return MessageBuilder.fromMessage(failed)
.setHeader(X_RETRIES_HEADER, new Integer(retries.intValue() + 1))
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build();
}
else {
System.out.println("Retries exhausted for " + failed);
parkingLot.send(MessageBuilder.fromMessage(failed)
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build());
}
return null;
}
@Override
public void run(String... args) throws Exception {
while (true) {
int count = this.processed.get();
Thread.sleep(5000);
if (count == this.processed.get()) {
System.out.println("Idle, terminating");
return;
}
}
}
public interface TwoOutputProcessor extends Processor {
@Output("parkingLot")
MessageChannel parkingLot();
}
}1.12. 使用 Kafka 绑定器进行分区
Apache Kafka 原生支持主题分区。
有时将数据发送到特定分区是有利的——例如,当你希望严格排序消息处理时(特定客户的所有消息都应该发送到同一分区)。
以下示例展示了如何配置 producer 和 consumer 端
@SpringBootApplication
@EnableBinding(Source.class)
public class KafkaPartitionProducerApplication {
private static final Random RANDOM = new Random(System.currentTimeMillis());
private static final String[] data = new String[] {
"foo1", "bar1", "qux1",
"foo2", "bar2", "qux2",
"foo3", "bar3", "qux3",
"foo4", "bar4", "qux4",
};
public static void main(String[] args) {
new SpringApplicationBuilder(KafkaPartitionProducerApplication.class)
.web(false)
.run(args);
}
@InboundChannelAdapter(channel = Source.OUTPUT, poller = @Poller(fixedRate = "5000"))
public Message<?> generate() {
String value = data[RANDOM.nextInt(data.length)];
System.out.println("Sending: " + value);
return MessageBuilder.withPayload(value)
.setHeader("partitionKey", value)
.build();
}
}spring:
cloud:
stream:
bindings:
output:
destination: partitioned.topic
producer:
partition-key-expression: headers['partitionKey']
partition-count: 12主题必须预先配置足够的分区,以满足所有消费者组所需的并发度。上述配置支持最多 12 个消费者实例(如果 concurrency 为 2,则支持 6 个;如果并发度为 3,则支持 4 个,依此类推)。通常最好“过度配置”分区,以便未来增加消费者或并发度。 |
上述配置使用了默认分区策略(key.hashCode() % partitionCount)。这可能提供或不提供一个适当平衡的算法,具体取决于键值。你可以通过使用 partitionSelectorExpression 或 partitionSelectorClass 属性来覆盖此默认设置。 |
由于分区由 Kafka 原生处理,消费者端无需特殊配置。Kafka 会在实例之间分配分区。
以下 Spring Boot 应用程序监听 Kafka 流,并将每条消息发送到的分区 ID 打印到控制台
@SpringBootApplication
@EnableBinding(Sink.class)
public class KafkaPartitionConsumerApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(KafkaPartitionConsumerApplication.class)
.web(false)
.run(args);
}
@StreamListener(Sink.INPUT)
public void listen(@Payload String in, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) {
System.out.println(in + " received from partition " + partition);
}
}spring:
cloud:
stream:
bindings:
input:
destination: partitioned.topic
group: myGroup你可以根据需要添加实例。Kafka 会重新平衡分区分配。如果实例数量(或 instance count * concurrency)超过分区数量,一些消费者将处于空闲状态。
2. Kafka Streams 绑定器
2.1. 用法
要使用 Kafka Streams binder,只需将其添加到你的 Spring Cloud Stream 应用程序中,使用以下 Maven 坐标
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka-streams</artifactId>
</dependency>快速启动一个用于 Kafka Streams binder 的新项目的方法是使用Spring Initializr,然后选择“Cloud Streams”和“Spring for Kafka Streams”,如下所示

2.2. 概述
Spring Cloud Stream 包含一个专门为Apache Kafka Streams 绑定设计的 binder 实现。通过这种原生集成,Spring Cloud Stream 的“processor”应用程序可以在核心业务逻辑中直接使用Apache Kafka Streams API。
Kafka Streams binder 实现构建在Spring for Apache Kafka 项目提供的基础上。
Kafka Streams binder 为 Kafka Streams 中的三种主要类型提供绑定能力——KStream、KTable 和 GlobalKTable。
Kafka Streams 应用程序通常遵循一种模式:从入站主题读取记录,应用业务逻辑,然后将转换后的记录写入出站主题。或者,也可以定义一个没有出站目标的 Processor 应用程序。
在接下来的章节中,我们将详细介绍 Spring Cloud Stream 与 Kafka Streams 的集成。
2.3. 编程模型
使用 Kafka Streams binder 提供的编程模型时,可以使用高级的Streams DSL,也可以混合使用高级和低级的Processor-API。混合使用高级和低级 API 通常通过在 KStream 上调用 transform 或 process API 方法来实现。
2.3.1. 函数式风格
从 Spring Cloud Stream 3.0.0 版本开始,Kafka Streams binder 允许应用程序使用 Java 8 中提供的函数式编程风格进行设计和开发。这意味着应用程序可以简洁地表示为类型为 java.util.function.Function 或 java.util.function.Consumer 的 lambda 表达式。
让我们看一个非常基础的例子。
@SpringBootApplication
public class SimpleConsumerApplication {
@Bean
public java.util.function.Consumer<KStream<Object, String>> process() {
return input ->
input.foreach((key, value) -> {
System.out.println("Key: " + key + " Value: " + value);
});
}
}虽然简单,但这是一个完整的独立 Spring Boot 应用程序,它利用 Kafka Streams 进行流处理。这是一个消费者应用程序,没有出站绑定,只有一个入站绑定。应用程序消费数据,并简单地将来自 KStream 键和值的信息记录到标准输出。应用程序包含 SpringBootApplication 注解和一个被标记为 Bean 的方法。该 bean 方法的类型是 java.util.function.Consumer,它使用 KStream 进行参数化。然后在实现中,我们返回一个 Consumer 对象,它本质上是一个 lambda 表达式。在 lambda 表达式内部,提供了处理数据的代码。
在此应用程序中,有一个类型为 KStream 的单一输入绑定。binder 为此应用程序创建一个名为 process-in-0 的绑定,即函数 bean 名称后跟一个破折号字符 (-),然后是文字 in,再后跟一个破折号和参数的序数位置。你使用此绑定名称来设置其他属性,例如目的地。例如,spring.cloud.stream.bindings.process-in-0.destination=my-topic。
| 如果未在绑定上设置 destination 属性,则会创建一个与绑定同名的主题(如果应用程序有足够的权限),或者期望该主题已存在。 |
一旦构建为 uber-jar(例如 kstream-consumer-app.jar),就可以按如下方式运行上述示例。
java -jar kstream-consumer-app.jar --spring.cloud.stream.bindings.process-in-0.destination=my-topic这是另一个示例,它是一个具有输入和输出绑定的完整 processor。这是经典的词频统计示例,应用程序从主题接收数据,然后在 tumbling time-window 中计算每个单词的出现次数。
@SpringBootApplication
public class WordCountProcessorApplication {
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>> process() {
return input -> input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.map((key, value) -> new KeyValue<>(value, value))
.groupByKey(Serialized.with(Serdes.String(), Serdes.String()))
.windowedBy(TimeWindows.of(5000))
.count(Materialized.as("word-counts-state-store"))
.toStream()
.map((key, value) -> new KeyValue<>(key.key(), new WordCount(key.key(), value,
new Date(key.window().start()), new Date(key.window().end()))));
}
public static void main(String[] args) {
SpringApplication.run(WordCountProcessorApplication.class, args);
}
}这里同样,基本主题与之前的示例相同,但这里我们有两个输入。Java 的 BiFunction 支持用于将输入绑定到期望的目的地。binder 为输入生成的默认绑定名称分别是 process-in-0 和 process-in-1。默认输出绑定是 process-out-0。在此示例中,BiFunction 的第一个参数被绑定为第一个输入的 KStream,第二个参数被绑定为第二个输入的 KTable。
一旦构建为 uber-jar(例如 wordcount-processor.jar),就可以按如下方式运行上述示例。
java -jar wordcount-processor.jar --spring.cloud.stream.bindings.process-in-0.destination=words --spring.cloud.stream.bindings.process-out-0.destination=counts此应用程序将从 Kafka 主题 words 消费消息,并将计算结果发布到输出主题 counts。
Spring Cloud Stream 将确保来自入站和出站主题的消息自动绑定为 KStream 对象。作为开发人员,你可以专注于代码的业务方面,即编写 processor 中所需的逻辑。由 Kafka Streams 基础设施所需的 Kafka Streams 特定配置的设置由框架自动处理。
我们上面看到的两个示例都有一个单一的 KStream 输入绑定。在这两种情况下,绑定都从一个主题接收记录。如果你想将多个主题复用到一个单一的 KStream 绑定中,可以在下方提供逗号分隔的 Kafka 主题作为目的地。
spring.cloud.stream.bindings.process-in-0.destination=topic-1,topic-2,topic-3
此外,如果你想根据正则表达式匹配主题,还可以提供主题模式作为目的地。
spring.cloud.stream.bindings.process-in-0.destination=input.*
多个输入绑定
许多非简单的 Kafka Streams 应用程序通常通过多个绑定从多个主题消费数据。例如,一个主题被消费为 KStream,另一个则被消费为 KTable 或 GlobalKTable。应用程序希望将数据接收为表类型有很多原因。考虑一个用例,其中底层主题是通过数据库的变更数据捕获 (CDC) 机制填充的,或者应用程序可能只关心最新的更新以进行下游处理。如果应用程序指定数据需要绑定为 KTable 或 GlobalKTable,那么 Kafka Streams binder 将正确地将目的地绑定到 KTable 或 GlobalKTable,并使它们可用于应用程序进行操作。我们将研究 Kafka Streams binder 中如何处理多个输入绑定的一些不同场景。
Kafka Streams Binder 中的 BiFunction
这里是一个我们有两个输入和一个输出的示例。在这种情况下,应用程序可以利用 java.util.function.BiFunction。
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
return (userClicksStream, userRegionsTable) -> (userClicksStream
.leftJoin(userRegionsTable, (clicks, region) -> new RegionWithClicks(region == null ?
"UNKNOWN" : region, clicks),
Joined.with(Serdes.String(), Serdes.Long(), null))
.map((user, regionWithClicks) -> new KeyValue<>(regionWithClicks.getRegion(),
regionWithClicks.getClicks()))
.groupByKey(Grouped.with(Serdes.String(), Serdes.Long()))
.reduce(Long::sum)
.toStream());
}这里同样,基本主题与之前的示例相同,但这里我们有两个输入。Java 的 BiFunction 支持用于将输入绑定到期望的目的地。binder 为输入生成的默认绑定名称分别是 process-in-0 和 process-in-1。默认输出绑定是 process-out-0。在此示例中,BiFunction 的第一个参数被绑定为第一个输入的 KStream,第二个参数被绑定为第二个输入的 KTable。
Kafka Streams Binder 中的 BiConsumer
如果有两个输入但没有输出,在这种情况下我们可以使用 java.util.function.BiConsumer,如下所示。
@Bean
public BiConsumer<KStream<String, Long>, KTable<String, String>> process() {
return (userClicksStream, userRegionsTable) -> {}
}超过两个输入
如果你有超过两个输入怎么办?在某些情况下你需要超过两个输入。在这种情况下,binder 允许你链式调用部分函数。在函数式编程术语中,这种技术通常被称为 currying(柯里化)。随着 Java 8 添加了函数式编程支持,Java 现在允许你编写 curried 函数。Spring Cloud Stream Kafka Streams binder 可以利用此特性来实现多个输入绑定。
让我们看一个例子。
@Bean
public Function<KStream<Long, Order>,
Function<GlobalKTable<Long, Customer>,
Function<GlobalKTable<Long, Product>, KStream<Long, EnrichedOrder>>>> enrichOrder() {
return orders -> (
customers -> (
products -> (
orders.join(customers,
(orderId, order) -> order.getCustomerId(),
(order, customer) -> new CustomerOrder(customer, order))
.join(products,
(orderId, customerOrder) -> customerOrder
.productId(),
(customerOrder, product) -> {
EnrichedOrder enrichedOrder = new EnrichedOrder();
enrichedOrder.setProduct(product);
enrichedOrder.setCustomer(customerOrder.customer);
enrichedOrder.setOrder(customerOrder.order);
return enrichedOrder;
})
)
)
);
}让我们看看上面介绍的绑定模型的细节。在此模型中,我们在入站端有 3 个部分应用的函数。我们将它们称为 f(x)、f(y) 和 f(z)。如果我们将这些函数按真实数学函数的意义展开,它将看起来像这样:f(x) → (fy) → f(z) → KStream<Long, EnrichedOrder>。变量 x 代表 KStream<Long, Order>,变量 y 代表 GlobalKTable<Long, Customer>,变量 z 代表 GlobalKTable<Long, Product>。第一个函数 f(x) 接收应用程序的第一个输入绑定(KStream<Long, Order>),其输出是函数 f(y)。函数 f(y) 接收应用程序的第二个输入绑定(GlobalKTable<Long, Customer>),其输出是另一个函数 f(z)。函数 f(z) 的输入是应用程序的第三个输入(GlobalKTable<Long, Product>),其输出是 KStream<Long, EnrichedOrder>,这是应用程序的最终输出绑定。来自三个部分函数(分别是 KStream、GlobalKTable、GlobalKTable)的输入都在方法体中可供你使用,以实现 lambda 表达式中的业务逻辑。
输入绑定分别命名为 enrichOrder-in-0、enrichOrder-in-1 和 enrichOrder-in-2。输出绑定命名为 enrichOrder-out-0。
使用 curried 函数,你实际上可以拥有任意数量的输入。但是,请记住,在 Java 中,超过少量输入及其部分应用函数(如上所示)可能会导致代码难以阅读。因此,如果你的 Kafka Streams 应用程序需要超过合理范围的少量输入绑定,并且你想使用这种函数式模型,那么你可能需要重新考虑你的设计并适当分解应用程序。
多个输出绑定
Kafka Streams 允许将出站数据写入多个主题。此功能在 Kafka Streams 中被称为分支 (branching)。使用多个输出绑定时,你需要提供一个 KStream 数组(KStream[])作为出站返回类型。
这里是一个示例
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>[]> process() {
Predicate<Object, WordCount> isEnglish = (k, v) -> v.word.equals("english");
Predicate<Object, WordCount> isFrench = (k, v) -> v.word.equals("french");
Predicate<Object, WordCount> isSpanish = (k, v) -> v.word.equals("spanish");
return input -> input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(TimeWindows.of(5000))
.count(Materialized.as("WordCounts-branch"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value,
new Date(key.window().start()), new Date(key.window().end()))))
.branch(isEnglish, isFrench, isSpanish);
}编程模型保持不变,但出站参数化类型是 KStream[]。默认输出绑定名称分别是 process-out-0、process-out-1、process-out-2。binder 生成三个输出绑定的原因是它检测到了返回的 KStream 数组的长度。
Kafka Streams 基于函数的编程风格总结
总之,下表显示了函数式范例中可以使用的各种选项。
| 输入数量 | 输出数量 | 使用的组件 |
|---|---|---|
1 |
0 |
java.util.function.Consumer |
2 |
0 |
java.util.function.BiConsumer |
1 |
1..n |
java.util.function.Function |
2 |
1..n |
java.util.function.BiFunction |
>= 3 |
0..n |
使用 curried 函数 |
-
在此表中,如果输出数量大于一,则类型简单地变为
KStream[]。
2.3.2. 命令式编程模型。
尽管上面概述的函数式编程模型是首选方法,如果你愿意,仍然可以使用经典的基于 StreamListener 的方法。
这里有一些示例。
以下是使用 StreamListener 实现的词频统计示例的等价版本。
@SpringBootApplication
@EnableBinding(KafkaStreamsProcessor.class)
public class WordCountProcessorApplication {
@StreamListener("input")
@SendTo("output")
public KStream<?, WordCount> process(KStream<?, String> input) {
return input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(TimeWindows.of(5000))
.count(Materialized.as("WordCounts-multi"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))));
}
public static void main(String[] args) {
SpringApplication.run(WordCountProcessorApplication.class, args);
}如你所见,这有点冗长,因为你需要提供 EnableBinding 以及其他额外的注解,如 StreamListener 和 SendTo,才能构成一个完整的应用程序。EnableBinding 用于指定包含绑定的绑定接口。在此示例中,我们使用了内置的 KafkaStreamsProcessor 绑定接口,它具有以下契约。
public interface KafkaStreamsProcessor {
@Input("input")
KStream<?, ?> input();
@Output("output")
KStream<?, ?> output();
}Binder 将为输入 KStream 和输出 KStream 创建绑定,因为你使用的绑定接口包含这些声明。
除了函数式风格提供的编程模型上的明显差异之外,这里需要提及的一个特别之处在于绑定名称是你指定在绑定接口中的名称。例如,在上面的应用程序中,由于我们使用了 KafkaStreamsProcessor,绑定名称是 input 和 output。绑定属性需要使用这些名称。例如 spring.cloud.stream.bindings.input.destination、spring.cloud.stream.bindings.output.destination 等。请记住,这与函数式风格根本不同,因为在函数式风格中,binder 会为应用程序生成绑定名称。这是因为应用程序在使用 EnableBinding 的函数式模型中不提供任何绑定接口。
这是另一个有两个输入的 sink 示例。
@EnableBinding(KStreamKTableBinding.class)
.....
.....
@StreamListener
public void process(@Input("inputStream") KStream<String, PlayEvent> playEvents,
@Input("inputTable") KTable<Long, Song> songTable) {
....
....
}
interface KStreamKTableBinding {
@Input("inputStream")
KStream<?, ?> inputStream();
@Input("inputTable")
KTable<?, ?> inputTable();
}以下是上面看到的基于 BiFunction 的 processor 的 StreamListener 等价版本。
@EnableBinding(KStreamKTableBinding.class)
....
....
@StreamListener
@SendTo("output")
public KStream<String, Long> process(@Input("input") KStream<String, Long> userClicksStream,
@Input("inputTable") KTable<String, String> userRegionsTable) {
....
....
}
interface KStreamKTableBinding extends KafkaStreamsProcessor {
@Input("inputX")
KTable<?, ?> inputTable();
}最后,这里是具有三个输入和 curried 函数的应用程序的 StreamListener 等价版本。
@EnableBinding(CustomGlobalKTableProcessor.class)
...
...
@StreamListener
@SendTo("output")
public KStream<Long, EnrichedOrder> process(
@Input("input-1") KStream<Long, Order> ordersStream,
@Input("input-2") GlobalKTable<Long, Customer> customers,
@Input("input-3") GlobalKTable<Long, Product> products) {
KStream<Long, CustomerOrder> customerOrdersStream = ordersStream.join(
customers, (orderId, order) -> order.getCustomerId(),
(order, customer) -> new CustomerOrder(customer, order));
return customerOrdersStream.join(products,
(orderId, customerOrder) -> customerOrder.productId(),
(customerOrder, product) -> {
EnrichedOrder enrichedOrder = new EnrichedOrder();
enrichedOrder.setProduct(product);
enrichedOrder.setCustomer(customerOrder.customer);
enrichedOrder.setOrder(customerOrder.order);
return enrichedOrder;
});
}
interface CustomGlobalKTableProcessor {
@Input("input-1")
KStream<?, ?> input1();
@Input("input-2")
GlobalKTable<?, ?> input2();
@Input("input-3")
GlobalKTable<?, ?> input3();
@Output("output")
KStream<?, ?> output();
}你可能会注意到,上面两个示例更加冗长,因为除了提供 EnableBinding 之外,你还需要编写自己的自定义绑定接口。使用函数式模型,可以避免所有这些仪式性的细节。
在我们继续探讨 Kafka Streams binder 提供的通用编程模型之前,这里是多个输出绑定的 StreamListener 版本。
EnableBinding(KStreamProcessorWithBranches.class)
public static class WordCountProcessorApplication {
@Autowired
private TimeWindows timeWindows;
@StreamListener("input")
@SendTo({"output1","output2","output3"})
public KStream<?, WordCount>[] process(KStream<Object, String> input) {
Predicate<Object, WordCount> isEnglish = (k, v) -> v.word.equals("english");
Predicate<Object, WordCount> isFrench = (k, v) -> v.word.equals("french");
Predicate<Object, WordCount> isSpanish = (k, v) -> v.word.equals("spanish");
return input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(timeWindows)
.count(Materialized.as("WordCounts-1"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))))
.branch(isEnglish, isFrench, isSpanish);
}
interface KStreamProcessorWithBranches {
@Input("input")
KStream<?, ?> input();
@Output("output1")
KStream<?, ?> output1();
@Output("output2")
KStream<?, ?> output2();
@Output("output3")
KStream<?, ?> output3();
}
}回顾一下,我们已经回顾了使用 Kafka Streams binder 时的各种编程模型选择。
binder 为输入提供 KStream、KTable 和 GlobalKTable 的绑定能力。KTable 和 GlobalKTable 绑定仅在输入端可用。Binder 支持 KStream 的输入和输出绑定。
Kafka Streams binder 编程模型的要点在于,binder 提供了灵活性,你可以选择完全函数式编程模型,或者使用基于 StreamListener 的命令式方法。
2.4. 编程模型的辅助功能
2.4.1. 单个应用程序中的多个 Kafka Streams 处理器
Binder 允许在单个 Spring Cloud Stream 应用程序中包含多个 Kafka Streams processor。你可以拥有如下所示的应用程序。
@Bean
public java.util.function.Function<KStream<Object, String>, KStream<Object, String>> process() {
...
}
@Bean
public java.util.function.Consumer<KStream<Object, String>> anotherProcess() {
...
}
@Bean
public java.util.function.BiFunction<KStream<Object, String>, KTable<Integer, String>, KStream<Object, String>> yetAnotherProcess() {
...
}在这种情况下,binder 将创建 3 个具有不同 application ID 的独立 Kafka Streams 对象(更多内容见下文)。但是,如果应用程序中有一个以上的 processor,你必须告诉 Spring Cloud Stream 哪些函数需要被激活。以下是激活函数的方法。
spring.cloud.stream.function.definition: process;anotherProcess;yetAnotherProcess
如果你希望某些函数不立即激活,可以将其从列表中移除。
当你在同一个应用程序中有一个单一的 Kafka Streams processor 和其他类型通过不同 binder 处理的 Function bean 时(例如,基于常规 Kafka Message Channel binder 的函数 bean),这也适用。
2.4.2. Kafka Streams 应用 ID
Application ID 是 Kafka Streams 应用程序必须提供的强制属性。Spring Cloud Stream Kafka Streams binder 允许你通过多种方式配置此 application ID。
如果应用程序中只有一个 processor 或 StreamListener,则可以使用以下属性在 binder 级别进行设置
spring.cloud.stream.kafka.streams.binder.applicationId.
为了方便起见,如果你只有一个 processor,还可以使用 spring.application.name 作为属性来委托设置 application ID。
如果应用程序中有多个 Kafka Streams processor,则需要为每个 processor 设置 application ID。对于函数式模型,可以将其作为属性附加到每个函数上。
例如,假设你有以下函数。
@Bean
public java.util.function.Consumer<KStream<Object, String>> process() {
...
}和
@Bean
public java.util.function.Consumer<KStream<Object, String>> anotherProcess() {
...
}然后,你可以使用以下 binder 级别属性为每个函数设置 application ID。
spring.cloud.stream.kafka.streams.binder.functions.process.applicationId
和
spring.cloud.stream.kafka.streams.binder.functions.anotherProcess.applicationId
对于 StreamListener,你需要将其设置在 processor 的第一个输入绑定上。
例如,假设你有以下两个基于 StreamListener 的 processor。
@StreamListener
@SendTo("output")
public KStream<String, String> process(@Input("input") <KStream<Object, String>> input) {
...
}
@StreamListener
@SendTo("anotherOutput")
public KStream<String, String> anotherProcess(@Input("anotherInput") <KStream<Object, String>> input) {
...
}那么你必须使用以下绑定属性来设置其 application ID。
spring.cloud.stream.kafka.streams.bindings.input.consumer.applicationId
和
spring.cloud.stream.kafka.streams.bindings.anotherInput.consumer.applicationId
对于基于函数的模型,这种在绑定级别设置 application ID 的方法也适用。然而,如果你使用函数式模型,像我们上面看到的那样在 binder 级别按函数设置要容易得多。
对于生产环境部署,强烈建议通过配置显式指定 application ID。如果你正在自动伸缩应用程序,这一点尤其重要,在这种情况下,你需要确保每个实例都使用相同的 application ID 进行部署。
如果应用程序没有提供 application ID,那么在这种情况下,binder 会自动为你生成一个静态 application ID。这在开发场景中很方便,因为它避免了显式提供 application ID 的需要。通过这种方式生成的 application ID 在应用程序重启后将保持静态。对于函数式模型,生成的 application ID 将是函数 bean 名称后跟文字 applicationID,例如如果函数 bean 名称是 process,则生成的 ID 是 process-applicationID。对于 StreamListener,生成的 application ID 不使用函数 bean 名称,而是使用包含类名后跟方法名,再后跟文字 applicationId。
设置应用 ID 总结
-
默认情况下,binder 将为每个函数或
StreamListener方法自动生成 application ID。 -
如果你有一个单一的 processor,那么可以使用
spring.kafka.streams.applicationId、spring.application.name或spring.cloud.stream.kafka.streams.binder.applicationId。 -
如果你有多个 processor,则可以使用属性 -
spring.cloud.stream.kafka.streams.binder.functions.<function-name>.applicationId为每个函数设置 application ID。对于StreamListener,可以使用spring.cloud.stream.kafka.streams.bindings.input.applicationId来完成,假设输入绑定名称是input。
2.4.3. 使用函数式风格覆盖绑定器生成的默认绑定名称
默认情况下,使用函数式风格时,binder 使用上面讨论的策略来生成绑定名称,即 <function-bean-name>-<in>|<out>-[0..n],例如 process-in-0, process-out-0 等。如果你想覆盖这些绑定名称,可以通过指定以下属性来实现。
spring.cloud.stream.function.bindings.<default binding name>。默认绑定名称是 binder 生成的原始绑定名称。
例如,假设你有这个函数。
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
...
}Binder 将生成名为 process-in-0、process-in-1 和 process-out-0 的绑定。现在,如果你想将它们完全更改为其他名称,也许是更具领域特定性的绑定名称,则可以按如下方式进行。
spring.cloud.stream.function.bindings.process-in-0=users
spring.cloud.stream.function.bindings.process-in-0=regions
和
spring.cloud.stream.function.bindings.process-out-0=clicks
之后,必须在这些新的绑定名称上设置所有绑定级别属性。
请记住,使用上面描述的函数式编程模型时,在大多数情况下遵循默认绑定名称是有意义的。你可能仍然想进行这种覆盖的唯一原因是你拥有大量的配置属性,并且希望将绑定映射到更具领域友好性的名称。
2.4.4. 设置引导服务器配置
运行 Kafka Streams 应用程序时,必须提供 Kafka broker 服务器信息。如果你没有提供此信息,binder 会默认期望 broker 运行在 localhost:9092。如果不是这种情况,则需要覆盖此设置。有几种方法可以做到这一点。
-
使用 boot 属性 -
spring.kafka.bootstrapServers -
Binder 级别属性 -
spring.cloud.stream.kafka.streams.binder.brokers
对于 binder 级别属性,无论你是否使用通过常规 Kafka binder 提供的 broker 属性 - spring.cloud.stream.kafka.binder.brokers 都没有关系。Kafka Streams binder 首先会检查是否设置了 Kafka Streams binder 特定的 broker 属性(spring.cloud.stream.kafka.streams.binder.brokers),如果找不到,则会查找 spring.cloud.stream.kafka.binder.brokers。
2.5. 记录序列化和反序列化
Kafka Streams binder 允许你通过两种方式序列化和反序列化记录。一种是 Kafka 提供的原生序列化和反序列化功能,另一种是 Spring Cloud Stream 框架的消息转换能力。让我们来看一些细节。
2.5.1. 入站反序列化
键始终使用原生 Serdes 进行反序列化。
对于值,默认情况下,入站的反序列化由 Kafka 原生执行。请注意,这是与之前版本 Kafka Streams binder 的默认行为的重大改变,之前版本的反序列化是由框架完成的。
Kafka Streams binder 将尝试通过查看 java.util.function.Function|Consumer 或 StreamListener 的类型签名来推断匹配的 Serde 类型。以下是它匹配 Serdes 的顺序。
-
如果应用程序提供一个类型为
Serde的 bean,并且返回类型使用传入键或值类型的实际类型进行参数化,那么它将使用该Serde进行入站反序列化。例如,如果应用程序中有以下内容,binder 会检测到KStream的传入值类型与Serdebean 上参数化的类型匹配。它将使用该 Serde 进行入站反序列化。
@Bean
public Serde<Foo() customSerde{
...
}
@Bean
public Function<KStream<String, Foo>, KStream<String, Foo>> process() {
}-
接下来,它会查看类型,检查它们是否是 Kafka Streams 公开的类型之一。如果是,则使用它们。以下是 binder 将尝试从 Kafka Streams 匹配的 Serde 类型。
Integer, Long, Short, Double, Float, byte[], UUID and String.
-
Kafka Streams 提供的 Serdes 如果都不匹配类型,那么将使用 Spring Kafka 提供的 JsonSerde。在这种情况下,绑定器假定类型是 JSON 友好的。如果您有多个值对象作为输入,这将非常有用,因为绑定器会在内部将它们推断为正确的 Java 类型。但在回退到
JsonSerde之前,绑定器会检查 Kafka Streams 配置中设置的默认Serde,以查看它是否可以与传入的 KStream 类型匹配。
如果上述策略都不奏效,那么应用程序必须通过配置提供 `Serde`。这可以通过两种方式进行配置 - 绑定级别或默认级别。
首先,绑定器将查看是否在绑定级别提供了 Serde。例如,如果您有以下处理器:
@Bean
public BiFunction<KStream<CustomKey, AvroIn1>, KTable<CustomKey, AvroIn2>, KStream<CustomKey, AvroOutput>> process() {...}那么,您可以使用以下方式提供绑定级别的 Serde:
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.keySerde=CustomKeySerde
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.valueSerde=io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.keySerde=CustomKeySerde
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.valueSerde=io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde如果您按上述方式为每个输入绑定提供了 Serde,则该配置将具有更高的优先级,并且绑定器将不会进行任何 Serde 推断。 |
如果您希望将默认的 key/value Serdes 用于入站反序列化,可以在绑定器级别进行设置。
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde
spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde如果您不希望使用 Kafka 提供的原生解码,可以依赖 Spring Cloud Stream 提供的消息转换功能。由于原生解码是默认设置,因此为了让 Spring Cloud Stream 反序列化入站值对象,您需要显式禁用原生解码。
例如,如果您有上面相同的 BiFunction 处理器,那么可以使用 spring.cloud.stream.bindings.process-in-0.consumer.nativeDecoding: false。您需要单独为所有输入禁用原生解码。否则,对于那些您没有禁用的输入,原生解码仍将应用。
默认情况下,Spring Cloud Stream 将使用 application/json 作为内容类型,并使用适当的 json 消息转换器。您可以通过使用以下属性和相应的 MessageConverter bean 来使用自定义消息转换器。
spring.cloud.stream.bindings.process-in-0.contentType2.5.2. 出站序列化
出站序列化与入站反序列化基本遵循相同的规则。与入站反序列化一样,Spring Cloud Stream 的一个主要变化是出站序列化现在由 Kafka 原生处理。在绑定器 3.0 版本之前,这是由框架本身完成的。
出站的 key 总是由 Kafka 使用绑定器推断出的匹配 Serde 进行序列化。如果无法推断 key 的类型,则需要通过配置指定。
值 Serdes 的推断使用与入站反序列化相同的规则。首先检查出站类型是否与应用程序中提供的 Bean 匹配。如果不匹配,则检查是否与 Kafka 暴露的 Serde(例如 - Integer, Long, Short, Double, Float, byte[], UUID 和 String)匹配。如果仍然不匹配,则回退到 Spring Kafka 项目提供的 JsonSerde,但在此之前会先查看默认的 Serde 配置是否存在匹配。请记住,所有这些对应用程序都是透明的。如果这些都不奏效,用户必须通过配置提供要使用的 Serde。
假设您正在使用上面相同的 BiFunction 处理器。那么您可以按如下方式配置出站 key/value Serdes。
spring.cloud.stream.kafka.streams.bindings.process-out-0.producer.keySerde=CustomKeySerde
spring.cloud.stream.kafka.streams.bindings.process-out-0.producer.valueSerde=io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde如果 Serde 推断失败,并且没有提供绑定级别的 Serdes,则绑定器回退到 JsonSerde,但会查找默认 Serdes 是否有匹配。
默认 serdes 的配置方式与上面描述的反序列化部分相同。
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde
如果您的应用程序使用分支功能并且有多个输出绑定,则需要为每个绑定单独配置。再次强调,如果绑定器能够推断 Serde 类型,则无需进行此配置。
如果您不希望使用 Kafka 提供的原生编码,但希望使用框架提供的消息转换,则需要显式禁用原生编码,因为原生编码是默认设置。例如,如果您有上面相同的 BiFunction 处理器,那么可以使用 spring.cloud.stream.bindings.process-out-0.producer.nativeEncoding: false。在分支的情况下,您需要单独为所有输出禁用原生编码。否则,对于那些您没有禁用的输出,原生编码仍将应用。
当由 Spring Cloud Stream 执行转换时,默认情况下,它将使用 application/json 作为内容类型,并使用适当的 json 消息转换器。您可以通过使用以下属性和相应的 MessageConverter bean 来使用自定义消息转换器。
spring.cloud.stream.bindings.process-out-0.contentType当禁用原生编码/解码时,绑定器将不会像原生 Serdes 那样进行任何推断。应用程序需要显式提供所有配置选项。因此,通常建议在编写 Spring Cloud Stream Kafka Streams 应用程序时,保持使用默认的序列化/反序列化选项,并坚持使用 Kafka Streams 提供的原生序列化/反序列化。您必须使用框架提供的消息转换功能的唯一场景是您的上游生产者使用了特定的序列化策略。在这种情况下,您需要使用匹配的反序列化策略,因为原生机制可能会失败。当依赖默认的 Serde 机制时,应用程序必须确保绑定器能够正确地将入站和出站类型映射到适当的 Serde,否则可能会失败。
值得一提的是,上面概述的数据序列化/反序列化方法仅适用于处理器的边缘,即 - 入站和出站。您的业务逻辑仍然可能需要调用 Kafka Streams API,这些 API 明确需要 Serde 对象。这些仍然是应用程序的责任,必须由开发人员相应地处理。
2.6. 错误处理
Apache Kafka Streams 提供了原生处理反序列化错误的异常处理能力。有关此支持的详细信息,请参阅 此处。开箱即用,Apache Kafka Streams 提供了两种反序列化异常处理器 - LogAndContinueExceptionHandler 和 LogAndFailExceptionHandler。顾名思义,前者会记录错误并继续处理下一条记录,后者会记录错误并失败。LogAndFailExceptionHandler 是默认的反序列化异常处理器。
2.6.1. 处理绑定器中的反序列化异常
Kafka Streams 绑定器允许使用以下属性指定上述反序列化异常处理器。
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler: logAndContinue或
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler: logAndFail除了上面两种反序列化异常处理器外,绑定器还提供了第三种,用于将错误记录(poison pills)发送到 DLQ(死信队列)主题。以下是启用此 DLQ 异常处理器的方法。
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler: sendToDlq设置上述属性后,所有反序列化错误的记录会自动发送到 DLQ 主题。
您可以通过以下方式设置 DLQ 消息发布的 topic 名称。
您可以提供一个 DlqDestinationResolver 的实现,这是一个函数式接口。DlqDestinationResolver 将 ConsumerRecord 和异常作为输入,然后允许指定一个 topic 名称作为输出。通过访问 Kafka ConsumerRecord,可以在 BiFunction 的实现中检查 header 记录。
以下是提供 DlqDestinationResolver 实现的示例。
@Bean
public DlqDestinationResolver dlqDestinationResolver() {
return (rec, ex) -> {
if (rec.topic().equals("word1")) {
return "topic1-dlq";
}
else {
return "topic2-dlq";
}
};
}提供 DlqDestinationResolver 的实现时,要记住一个重要的事情是,binder 中的 provisioner 不会自动为应用程序创建主题。这是因为 binder 无法推断出实现可能发送到的所有 DLQ 主题的名称。因此,如果你使用此策略提供 DLQ 名称,确保这些主题事先创建是应用程序的责任。
如果应用程序中存在 DlqDestinationResolver bean,则该 bean 具有更高的优先级。如果您不想遵循此方法,而是希望使用配置提供静态 DLQ 名称,可以设置以下属性。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.dlqName: custom-dlq (Change the binding name accordingly)如果设置了此属性,则错误记录将发送到 custom-dlq 主题。如果应用程序没有使用上述任何一种策略,它将创建一个名为 error.<input-topic-name>.<application-id> 的 DLQ 主题。例如,如果您的绑定目标主题是 inputTopic 并且应用程序 ID 是 process-applicationId,则默认的 DLQ 主题是 error.inputTopic.process-applicationId。如果您打算启用 DLQ,始终建议为每个输入绑定显式创建一个 DLQ 主题。
2.6.2. 每个输入消费者绑定的 DLQ
属性 spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler 适用于整个应用程序。这意味着如果同一应用程序中有多个函数或 StreamListener 方法,此属性将应用于所有这些方法。但是,如果您在单个处理器中有多个处理器或多个输入绑定,则可以使用绑定器为每个输入消费者绑定提供的更细粒度的 DLQ 控制。
如果您有以下处理器:
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
...
}并且您只想在第一个输入绑定上启用 DLQ,而在第二个绑定上启用 logAndSkip,则可以在消费者级别进行设置,如下所示。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.deserializationExceptionHandler: sendToDlq spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.deserializationExceptionHandler: logAndSkip
以这种方式设置反序列化异常处理器比在绑定器级别设置具有更高的优先级。
2.6.3. DLQ 分区
默认情况下,记录使用与原始记录相同的分区发布到死信主题。这意味着死信主题必须至少拥有与原始记录相同数量的分区。
要更改此行为,请将 DlqPartitionFunction 实现作为 `@Bean` 添加到应用程序上下文中。只能存在一个这样的 bean。该函数提供了消费者组(在大多数情况下与应用程序 ID 相同)、失败的 ConsumerRecord 和异常。例如,如果您总是希望路由到分区 0,可以使用:
@Bean
public DlqPartitionFunction partitionFunction() {
return (group, record, ex) -> 0;
}如果你将消费者绑定的 dlqPartitions 属性设置为 1(并且 binder 的 minPartitionCount 等于 1),则无需提供 DlqPartitionFunction;框架将始终使用分区 0。如果你将消费者绑定的 dlqPartitions 属性设置为大于 1 的值(或 binder 的 minPartitionCount 大于 1),则**必须**提供 DlqPartitionFunction bean,即使分区数量与原始主题相同。 |
在使用 Kafka Streams 绑定器中的异常处理功能时,需要牢记几点。
-
属性
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler适用于整个应用程序。这意味着如果同一应用程序中有多个函数或StreamListener方法,此属性将应用于所有这些方法。 -
反序列化的异常处理与原生反序列化和框架提供的消息转换保持一致。
2.6.4. 处理绑定器中的生产异常
与上面描述的反序列化异常处理支持不同,绑定器没有提供用于处理生产异常的此类一流机制。但是,您仍然可以使用 StreamsBuilderFactoryBean 定制器来配置生产异常处理器,您可以在下面的后续章节中找到更多详细信息。
2.7. 重试关键业务逻辑
有些场景您可能希望重试对应用程序至关重要的部分业务逻辑。可能是从 Kafka Streams 处理器调用关系型数据库或 REST 端点。这些调用可能由于网络问题或远程服务不可用等各种原因而失败。更常见的情况是,如果您可以再次尝试,这些故障可能会自行解决。默认情况下,Kafka Streams 绑定器会为所有输入绑定创建 RetryTemplate bean。
如果函数具有以下签名:
@Bean
public java.util.function.Consumer<KStream<Object, String>> process()并且使用默认绑定名称,RetryTemplate 将注册为 process-in-0-RetryTemplate。这遵循了绑定名称(process-in-0)后跟字面量 -RetryTemplate 的约定。在有多个输入绑定的情况下,每个绑定都会有一个单独的 RetryTemplate bean 可用。如果应用程序中存在自定义 RetryTemplate bean 并通过 spring.cloud.stream.bindings.<binding-name>.consumer.retryTemplateName 提供,则该 bean 优先于任何输入绑定级别的重试模板配置属性。
一旦绑定器中的 RetryTemplate 被注入到应用程序中,就可以用来重试应用程序的任何关键部分。以下是一个示例:
@Bean
public java.util.function.Consumer<KStream<Object, String>> process(@Lazy @Qualifier("process-in-0-RetryTemplate") RetryTemplate retryTemplate) {
return input -> input
.process(() -> new Processor<Object, String>() {
@Override
public void init(ProcessorContext processorContext) {
}
@Override
public void process(Object o, String s) {
retryTemplate.execute(context -> {
//Critical business logic goes here.
});
}
@Override
public void close() {
}
});
}或者您可以使用自定义 RetryTemplate 如下所示。
@EnableAutoConfiguration
public static class CustomRetryTemplateApp {
@Bean
@StreamRetryTemplate
RetryTemplate fooRetryTemplate() {
RetryTemplate retryTemplate = new RetryTemplate();
RetryPolicy retryPolicy = new SimpleRetryPolicy(4);
FixedBackOffPolicy backOffPolicy = new FixedBackOffPolicy();
backOffPolicy.setBackOffPeriod(1);
retryTemplate.setBackOffPolicy(backOffPolicy);
retryTemplate.setRetryPolicy(retryPolicy);
return retryTemplate;
}
@Bean
public java.util.function.Consumer<KStream<Object, String>> process() {
return input -> input
.process(() -> new Processor<Object, String>() {
@Override
public void init(ProcessorContext processorContext) {
}
@Override
public void process(Object o, String s) {
fooRetryTemplate().execute(context -> {
//Critical business logic goes here.
});
}
@Override
public void close() {
}
});
}
}注意,当重试耗尽时,默认情况下,将抛出最后一个异常,导致处理器终止。如果您希望处理异常并继续处理,可以将 RecoveryCallback 添加到 execute 方法中:以下是一个示例。
retryTemplate.execute(context -> {
//Critical business logic goes here.
}, context -> {
//Recovery logic goes here.
return null;
));有关 RetryTemplate、重试策略、回退策略等的更多信息,请参阅 Spring Retry 项目。
2.8. 状态存储
当使用高级 DSL 并调用触发状态存储的适当方法时,状态存储会由 Kafka Streams 自动创建。
如果您想将传入的 KTable 绑定物化为一个命名的状态存储,可以使用以下策略。
假设您有以下函数。
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
...
}然后通过设置以下属性,传入的 KTable 数据将被物化到命名的状态存储中。
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.materializedAs: incoming-store您可以在应用程序中将自定义状态存储定义为 bean,绑定器会检测到并将它们添加到 Kafka Streams builder 中。特别是在使用 Processor API 时,您需要手动注册状态存储。为此,您可以在应用程序中创建一个 StateStore bean。以下是定义此类 bean 的示例。
@Bean
public StoreBuilder myStore() {
return Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("my-store"), Serdes.Long(),
Serdes.Long());
}
@Bean
public StoreBuilder otherStore() {
return Stores.windowStoreBuilder(
Stores.persistentWindowStore("other-store",
1L, 3, 3L, false), Serdes.Long(),
Serdes.Long());
}这些状态存储随后可以直接由应用程序访问。
在引导过程中,上述 bean 将由绑定器处理并传递给 Streams builder 对象。
访问状态存储
Processor<Object, Product>() {
WindowStore<Object, String> state;
@Override
public void init(ProcessorContext processorContext) {
state = (WindowStore)processorContext.getStateStore("mystate");
}
...
}这不适用于注册全局状态存储。要注册全局状态存储,请参阅下面关于定制 StreamsBuilderFactoryBean 的章节。
2.9. 交互式查询
Kafka Streams 绑定器 API 暴露了一个名为 InteractiveQueryService 的类,用于交互式查询状态存储。您可以将其作为 Spring bean 在应用程序中访问。从应用程序访问此 bean 的简单方法是 autowire 该 bean。
@Autowired
private InteractiveQueryService interactiveQueryService;一旦您获得了此 bean 的访问权,就可以查询您感兴趣的特定状态存储。见下文。
ReadOnlyKeyValueStore<Object, Object> keyValueStore =
interactiveQueryService.getQueryableStoreType("my-store", QueryableStoreTypes.keyValueStore());在启动过程中,上述检索存储的方法调用可能会失败。例如,它可能仍在初始化状态存储的过程中。在这种情况下,重试此操作会很有用。Kafka Streams 绑定器提供了一个简单的重试机制来适应这种情况。
以下是可用于控制此重试的两个属性。
-
spring.cloud.stream.kafka.streams.binder.stateStoreRetry.maxAttempts - 默认值为
1。 -
spring.cloud.stream.kafka.streams.binder.stateStoreRetry.backOffInterval - 默认值为
1000毫秒。
如果有多个 Kafka Streams 应用程序实例正在运行,那么在交互式查询它们之前,您需要确定哪个应用程序实例托管您要查询的特定 key。InteractiveQueryService API 提供了识别主机信息的方法。
为了使这工作,您必须配置属性 application.server 如下所示:
spring.cloud.stream.kafka.streams.binder.configuration.application.server: <server>:<port>代码片段
org.apache.kafka.streams.state.HostInfo hostInfo = interactiveQueryService.getHostInfo("store-name",
key, keySerializer);
if (interactiveQueryService.getCurrentHostInfo().equals(hostInfo)) {
//query from the store that is locally available
}
else {
//query from the remote host
}2.9.1. 通过 InteractiveQueryService 可用的其他 API 方法
使用以下 API 方法检索与给定存储和 key 组合关联的 KeyQueryMetadata 对象。
public <K> KeyQueryMetadata getKeyQueryMetadata(String store, K key, Serializer<K> serializer)使用以下 API 方法检索与给定存储和 key 组合关联的 KakfaStreams 对象。
public <K> KafkaStreams getKafkaStreams(String store, K key, Serializer<K> serializer)2.10. 健康指示器
健康指示器需要依赖 spring-boot-starter-actuator。对于 Maven,请使用:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>Spring Cloud Stream Kafka Streams 绑定器提供了一个健康指示器来检查底层 streams 线程的状态。Spring Cloud Stream 定义了一个属性 management.health.binders.enabled 来启用健康指示器。请参阅 Spring Cloud Stream 文档。
健康指示器为每个 streams 线程的元数据提供以下详细信息:
-
线程名称
-
线程状态:
CREATED,RUNNING,PARTITIONS_REVOKED,PARTITIONS_ASSIGNED,PENDING_SHUTDOWN或DEAD -
活动任务:任务 ID 和分区
-
备用任务:任务 ID 和分区
默认情况下,只显示全局状态(UP 或 DOWN)。要显示详细信息,必须将属性 management.endpoint.health.show-details 设置为 ALWAYS 或 WHEN_AUTHORIZED。有关健康信息的更多详细信息,请参阅 Spring Boot Actuator 文档。
如果所有注册的 Kafka 线程都处于 RUNNING 状态,则健康指示器的状态为 UP。 |
由于 Kafka Streams 绑定器中有三种独立的绑定器类型(KStream、KTable 和 GlobalKTable),它们都将报告健康状态。当启用 show-details 时,报告的一些信息可能会冗余。
当同一应用程序中存在多个 Kafka Streams 处理器时,健康检查将针对所有处理器进行报告,并按 Kafka Streams 的应用程序 ID 进行分类。
2.11. 访问 Kafka Streams 指标
Spring Cloud Stream Kafka Streams 绑定器提供了 Kafka Streams 指标,可以通过 Micrometer MeterRegistry 导出。
对于 Spring Boot 2.2.x 版本,指标支持是通过绑定器提供的自定义 Micrometer 指标实现提供的。对于 Spring Boot 2.3.x 版本,Kafka Streams 指标支持通过 Micrometer 原生提供。
通过 Boot actuator 端点访问指标时,请确保将 metrics 添加到属性 management.endpoints.web.exposure.include 中。然后您可以访问 /actuator/metrics 获取所有可用指标的列表,然后可以通过相同的 URI(/actuator/metrics/<metric-name>)单独访问这些指标。
2.12. 混合使用高级 DSL 和低级 Processor API
Kafka Streams 提供了两种 API 变体。它有一个更高级别的 DSL 类似 API,您可以在其中链接各种操作,这对许多函数式编程人员来说可能很熟悉。Kafka Streams 还提供了对低级别 Processor API 的访问。Processor API 虽然功能非常强大,并且能够以低得多的级别控制事物,但本质上是命令式的。Spring Cloud Stream 的 Kafka Streams 绑定器允许您使用高级 DSL 或混合使用 DSL 和 Processor API。混合使用这两种变体为您提供了许多选项来控制应用程序中的各种用例。应用程序可以使用 transform 或 process 方法调用来访问 Processor API。
以下是使用 process API 在 Spring Cloud Stream 应用程序中结合使用 DSL 和 Processor API 的示例。
@Bean
public Consumer<KStream<Object, String>> process() {
return input ->
input.process(() -> new Processor<Object, String>() {
@Override
@SuppressWarnings("unchecked")
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(Object key, String value) {
//business logic
}
@Override
public void close() {
});
}以下是使用 transform API 的示例。
@Bean
public Consumer<KStream<Object, String>> process() {
return (input, a) ->
input.transform(() -> new Transformer<Object, String, KeyValue<Object, String>>() {
@Override
public void init(ProcessorContext context) {
}
@Override
public void close() {
}
@Override
public KeyValue<Object, String> transform(Object key, String value) {
// business logic - return transformed KStream;
}
});
}process API 方法调用是终端操作,而 transform API 是非终端操作,它可以返回一个可能经过转换的 KStream,您可以使用它继续使用 DSL 或 Processor API 进行进一步处理。
2.13. 出站分区支持
Kafka Streams 处理器通常将处理后的输出发送到出站 Kafka 主题。如果出站主题已分区,并且处理器需要将出站数据发送到特定分区,应用程序需要提供一个 StreamPartitioner 类型的 bean。有关详细信息,请参阅 StreamPartitioner。让我们看一些示例。
这就是我们已经多次看到的同一个处理器:
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>> process() {
...
}以下是出站绑定目标:
spring.cloud.stream.bindings.process-out-0.destination: outputTopic如果主题 outputTopic 有 4 个分区,如果您不提供分区策略,Kafka Streams 将使用默认分区策略,这可能不是您想要的,具体取决于特定的用例。假设您希望将匹配 spring 的任何 key 发送到分区 0,cloud 发送到分区 1,stream 发送到分区 2,其余所有发送到分区 3。这就是您需要在应用程序中执行的操作。
@Bean
public StreamPartitioner<String, WordCount> streamPartitioner() {
return (t, k, v, n) -> {
if (k.equals("spring")) {
return 0;
}
else if (k.equals("cloud")) {
return 1;
}
else if (k.equals("stream")) {
return 2;
}
else {
return 3;
}
};
}这是一个基本的实现,但是,您可以访问记录的 key/value、主题名称和总分区数。因此,如果需要,您可以实现复杂的分区策略。
您还需要将此 bean 名称与应用程序配置一起提供。
spring.cloud.stream.kafka.streams.bindings.process-out-0.producer.streamPartitionerBeanName: streamPartitioner应用程序中的每个输出主题都需要像这样单独配置。
2.14. StreamsBuilderFactoryBean 定制器
通常需要定制创建 KafkaStreams 对象的 StreamsBuilderFactoryBean。基于 Spring Kafka 提供的底层支持,绑定器允许您定制 StreamsBuilderFactoryBean。您可以使用 StreamsBuilderFactoryBeanCustomizer 来定制 StreamsBuilderFactoryBean 本身。然后,一旦通过此定制器访问到 StreamsBuilderFactoryBean,就可以使用 KafkaStreamsCustomizer 定制相应的 KafkaStreams。这两个定制器都是 Spring for Apache Kafka 项目的一部分。
以下是使用 StreamsBuilderFactoryBeanCustomizer 的示例。
@Bean
public StreamsBuilderFactoryBeanCustomizer streamsBuilderFactoryBeanCustomizer() {
return sfb -> sfb.setStateListener((newState, oldState) -> {
//Do some action here!
});
}上面展示了一个示例,说明了您可以如何定制 StreamsBuilderFactoryBean。本质上,您可以调用 StreamsBuilderFactoryBean 中任何可用的修改操作来对其进行定制。绑定器将在 factory bean 启动之前调用此定制器。
一旦您获得了 StreamsBuilderFactoryBean 的访问权,您也可以定制底层 KafkaStreams 对象。以下是这样做的蓝图。
@Bean
public StreamsBuilderFactoryBeanCustomizer streamsBuilderFactoryBeanCustomizer() {
return factoryBean -> {
factoryBean.setKafkaStreamsCustomizer(new KafkaStreamsCustomizer() {
@Override
public void customize(KafkaStreams kafkaStreams) {
kafkaStreams.setUncaughtExceptionHandler((t, e) -> {
});
}
});
};
}KafkaStreamsCustomizer 将在底层 KafkaStreams 启动之前由 StreamsBuilderFactoryBeabn 调用。
整个应用程序中只能有一个 StreamsBuilderFactoryBeanCustomizer。那么如何考虑多个 Kafka Streams 处理器呢,因为每个处理器都由独立的 StreamsBuilderFactoryBean 对象支持?在这种情况下,如果这些处理器需要不同的定制,应用程序需要基于应用程序 ID 应用一些过滤。
例如,
@Bean
public StreamsBuilderFactoryBeanCustomizer streamsBuilderFactoryBeanCustomizer() {
return factoryBean -> {
if (factoryBean.getStreamsConfiguration().getProperty(StreamsConfig.APPLICATION_ID_CONFIG)
.equals("processor1-application-id")) {
factoryBean.setKafkaStreamsCustomizer(new KafkaStreamsCustomizer() {
@Override
public void customize(KafkaStreams kafkaStreams) {
kafkaStreams.setUncaughtExceptionHandler((t, e) -> {
});
}
});
}
};2.14.1. 使用定制器注册全局状态存储
如上所述,绑定器没有提供一种一流的方式来注册全局状态存储作为一项功能。为此,您需要使用定制器。以下是如何做到这一点。
@Bean
public StreamsBuilderFactoryBeanCustomizer customizer() {
return fb -> {
try {
final StreamsBuilder streamsBuilder = fb.getObject();
streamsBuilder.addGlobalStore(...);
}
catch (Exception e) {
}
};
}再次强调,如果您有多个处理器,您需要通过过滤掉其他 StreamsBuilderFactoryBean 对象(如上所述使用应用程序 ID)将全局状态存储附加到正确的 StreamsBuilder。
2.14.2. 使用定制器注册生产异常处理器
在错误处理部分,我们提到绑定器没有提供一种一流的方式来处理生产异常。尽管如此,您仍然可以使用 StreamsBuilderFacotryBean 定制器来注册生产异常处理器。见下文。
@Bean
public StreamsBuilderFactoryBeanCustomizer customizer() {
return fb -> {
fb.getStreamsConfiguration().put(StreamsConfig.DEFAULT_PRODUCTION_EXCEPTION_HANDLER_CLASS_CONFIG,
CustomProductionExceptionHandler.class);
};
}再一次,如果您有多个处理器,您可能需要适当设置正确的 StreamsBuilderFactoryBean。您也可以使用配置属性添加此类生产异常处理器(更多内容见下文),但如果您选择采用编程式方法,这是一种选择。
2.15. 时间戳提取器
Kafka Streams 允许您根据各种时间戳概念控制消费者记录的处理。默认情况下,Kafka Streams 提取嵌入在消费者记录中的时间戳元数据。您可以通过为每个输入绑定提供不同的 TimestampExtractor 实现来更改此默认行为。以下是有关如何做到的一些详细信息。
@Bean
public Function<KStream<Long, Order>,
Function<KTable<Long, Customer>,
Function<GlobalKTable<Long, Product>, KStream<Long, Order>>>> process() {
return orderStream ->
customers ->
products -> orderStream;
}
@Bean
public TimestampExtractor timestampExtractor() {
return new WallclockTimestampExtractor();
}然后为每个消费者绑定设置上述 TimestampExtractor bean 名称。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.timestampExtractorBeanName=timestampExtractor
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.timestampExtractorBeanName=timestampExtractor
spring.cloud.stream.kafka.streams.bindings.process-in-2.consumer.timestampExtractorBeanName=timestampExtractor"如果您跳过某个输入消费者绑定以设置自定义时间戳提取器,该消费者将使用默认设置。
2.16. 具有 Kafka Streams 绑定器和常规 Kafka 绑定器的多绑定器
您可以在一个应用程序中同时拥有基于常规 Kafka 绑定器的函数/消费者/供应者和基于 Kafka Streams 的处理器。但是,您不能在单个函数或消费者中混合使用它们。
以下是同一应用程序中同时包含两种绑定器类型组件的示例。
@Bean
public Function<String, String> process() {
return s -> s;
}
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>> kstreamProcess() {
return input -> input;
}这是配置中的相关部分。
spring.cloud.stream.function.definition=process;kstreamProcess
spring.cloud.stream.bindings.process-in-0.destination=foo
spring.cloud.stream.bindings.process-out-0.destination=bar
spring.cloud.stream.bindings.kstreamProcess-in-0.destination=bar
spring.cloud.stream.bindings.kstreamProcess-out-0.destination=foobar如果您有与上面相同的应用程序,但处理两个不同的 Kafka 集群,例如,常规的 process 作用于集群 1 和集群 2(从集群 1 接收数据并发送到集群 2),而 Kafka Streams 处理器作用于集群 2。那么您必须使用 Spring Cloud Stream 提供的多绑定器功能。
在这种场景下,您的配置可能会发生如下变化。
# multi binder configuration
spring.cloud.stream.binders.kafka1.type: kafka
spring.cloud.stream.binders.kafka1.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-1} #Replace kafkaCluster-1 with the approprate IP of the cluster
spring.cloud.stream.binders.kafka2.type: kafka
spring.cloud.stream.binders.kafka2.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2} #Replace kafkaCluster-2 with the approprate IP of the cluster
spring.cloud.stream.binders.kafka3.type: kstream
spring.cloud.stream.binders.kafka3.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2} #Replace kafkaCluster-2 with the approprate IP of the cluster
spring.cloud.stream.function.definition=process;kstreamProcess
# From cluster 1 to cluster 2 with regular process function
spring.cloud.stream.bindings.process-in-0.destination=foo
spring.cloud.stream.bindings.process-in-0.binder=kafka1 # source from cluster 1
spring.cloud.stream.bindings.process-out-0.destination=bar
spring.cloud.stream.bindings.process-out-0.binder=kafka2 # send to cluster 2
# Kafka Streams processor on cluster 2
spring.cloud.stream.bindings.kstreamProcess-in-0.destination=bar
spring.cloud.stream.bindings.kstreamProcess-in-0.binder=kafka3
spring.cloud.stream.bindings.kstreamProcess-out-0.destination=foobar
spring.cloud.stream.bindings.kstreamProcess-out-0.binder=kafka3请注意上面的配置。我们有两种类型的绑定器,但总共有三个绑定器,第一个是基于集群 1 的常规 Kafka 绑定器(kafka1),然后是基于集群 2 的另一个 Kafka 绑定器(kafka2),最后是 kstream 类型的绑定器(kafka3)。应用程序中的第一个处理器从 kafka1 接收数据并发布到 kafka2,其中两个绑定器都基于常规 Kafka 绑定器,但连接到不同的集群。第二个处理器是 Kafka Streams 处理器,它从 kafka3 消费数据,kafka3 与 kafka2 是同一个集群,但绑定器类型不同。
由于 Kafka Streams 绑定器系列中有三种不同的绑定器类型 - kstream、ktable 和 globalktable - 如果您的应用程序有多个基于这些绑定器中的任何一个的绑定,则需要显式提供绑定器类型。
例如,如果您有以下处理器:
@Bean
public Function<KStream<Long, Order>,
Function<KTable<Long, Customer>,
Function<GlobalKTable<Long, Product>, KStream<Long, EnrichedOrder>>>> enrichOrder() {
...
}那么,这必须在多绑定器场景中配置如下。请注意,这仅在存在真正的多绑定器场景时才需要,即单个应用程序中存在处理多个集群的多个处理器。在这种情况下,需要为绑定显式提供绑定器,以便与来自其他处理器的绑定器类型和集群区分开来。
spring.cloud.stream.binders.kafka1.type: kstream
spring.cloud.stream.binders.kafka1.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2}
spring.cloud.stream.binders.kafka2.type: ktable
spring.cloud.stream.binders.kafka2.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2}
spring.cloud.stream.binders.kafka3.type: globalktable
spring.cloud.stream.binders.kafka3.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2}
spring.cloud.stream.bindings.enrichOrder-in-0.binder=kafka1 #kstream
spring.cloud.stream.bindings.enrichOrder-in-1.binder=kafka2 #ktablr
spring.cloud.stream.bindings.enrichOrder-in-2.binder=kafka3 #globalktable
spring.cloud.stream.bindings.enrichOrder-out-0.binder=kafka1 #kstream
# rest of the configuration is omitted.2.17. 状态清理
默认情况下,当绑定停止时会调用 Kafkastreams.cleanup() 方法。请参阅Spring Kafka 文档。要修改此行为,只需将一个 CleanupConfig `@Bean`(配置为在启动、停止或两者都不执行时进行清理)添加到应用程序上下文中即可;该 bean 将被检测到并注入到 factory bean 中。
2.18. Kafka Streams 拓扑可视化
Kafka Streams 绑定器提供了以下 actuator 端点,用于检索拓扑描述,您可以使用外部工具可视化该拓扑。
/actuator/kafkastreamstopology
/actuator/kafkastreamstopology/<application-id of the processor>
您需要包含 Spring Boot 的 actuator 和 web 依赖项才能访问这些端点。此外,您还需要将 kafkastreamstopology 添加到 management.endpoints.web.exposure.include 属性中。默认情况下,kafkastreamstopology 端点是禁用的。
2.19. 配置选项
本节包含 Kafka Streams 绑定器使用的配置选项。
有关绑定器的常见配置选项和属性,请参阅核心文档。
2.19.1. Kafka Streams 绑定器属性
以下属性可在绑定器级别使用,并且必须以 spring.cloud.stream.kafka.streams.binder. 为前缀。
- configuration
-
包含 Apache Kafka Streams API 相关属性的 key/value 对 Map。此属性必须以
spring.cloud.stream.kafka.streams.binder.为前缀。以下是使用此属性的一些示例。
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
spring.cloud.stream.kafka.streams.binder.configuration.commit.interval.ms=1000有关所有可用于 streams 配置的属性的更多信息,请参阅 Apache Kafka Streams 文档中的 StreamsConfig JavaDocs。您可以在 StreamsConfig 中设置的所有配置都可以通过此属性设置。使用此属性时,它适用于整个应用程序,因为这是绑定器级别的属性。如果应用程序中有多个处理器,所有处理器都将获取这些属性。对于像 application.id 这样的属性,这会带来问题,因此您必须仔细检查如何使用此绑定器级别的 configuration 属性映射 StreamsConfig 中的属性。
- functions.<function-bean-name>.applicationId
-
仅适用于函数式处理器。可用于在应用程序中为每个函数设置应用程序 ID。在有多个函数的情况下,这是一种方便的设置应用程序 ID 的方式。
- functions.<function-bean-name>.configuration
-
仅适用于函数式处理器。包含 Apache Kafka Streams API 相关属性的 key/value 对 Map。这类似于上面描述的绑定器级别的
configuration属性,但此级别的configuration属性仅限于命名的函数。当您有多个处理器并且希望基于特定函数限制对配置的访问时,您可能希望使用此属性。这里可以使用所有StreamsConfig属性。 - brokers
-
Broker URL
默认值:
localhost - zkNodes
-
Zookeeper URL
默认值:
localhost - deserializationExceptionHandler
-
反序列化错误处理器类型。此处理器应用于绑定器级别,因此适用于应用程序中的所有输入绑定。可以在消费者绑定级别以更细粒度的方式进行控制。可能的值有 -
logAndContinue、logAndFail或sendToDlq。默认值:
logAndFail - applicationId
-
方便地在 binder 级别全局设置 Kafka Streams 应用的
application.id。如果应用包含多个函数或StreamListener方法,则应以不同方式设置应用 ID。请参阅上面关于应用 ID 设置的详细讨论。默认值:应用将生成一个静态应用 ID。有关更多详细信息,请参阅应用 ID 部分。
- stateStoreRetry.maxAttempts
-
尝试连接状态存储的最大尝试次数。
默认值:1
- stateStoreRetry.backoffPeriod
-
重试时尝试连接状态存储的回退周期。
默认值:1000 ms
- consumerProperties
-
binder 级别的任意消费者属性。
- producerProperties
-
binder 级别的任意生产者属性。
2.19.2. Kafka Streams 生产者属性
以下属性仅适用于 Kafka Streams 生产者,并且必须以 spring.cloud.stream.kafka.streams.bindings.<binding name>.producer. 为前缀。为方便起见,如果存在多个输出 binding 并且它们都需要一个共同值,则可以使用前缀 spring.cloud.stream.kafka.streams.default.producer. 进行配置。
- keySerde
-
要使用的 key serde
默认值:请参阅上面关于消息反/序列化的讨论
- valueSerde
-
要使用的 value serde
默认值:请参阅上面关于消息反/序列化的讨论
- useNativeEncoding
-
启用/禁用原生编码的标志
默认值:
true。
streamPartitionerBeanName:要在消费者端使用的自定义出站分区器 bean 名称。应用可以将自定义的 StreamPartitioner 作为 Spring bean 提供,并将该 bean 的名称提供给生产者,以代替默认分区器。
+ 默认值:请参阅上面关于出站分区支持的讨论。
- producedAs
-
处理器生产到的 sink 组件的自定义名称。
默认值:
none(由 Kafka Streams 生成)
2.19.3. Kafka Streams 消费者属性
以下属性适用于 Kafka Streams 消费者,并且必须以 spring.cloud.stream.kafka.streams.bindings.<binding-name>.consumer. 为前缀。为方便起见,如果存在多个输入 binding 并且它们都需要一个共同值,则可以使用前缀 spring.cloud.stream.kafka.streams.default.consumer. 进行配置。
- applicationId
-
按输入 binding 设置 application.id。这仅适用于基于
StreamListener的处理器,对于基于函数的处理器,请参阅上面概述的其他方法。默认值:参见上文。
- keySerde
-
要使用的 key serde
默认值:请参阅上面关于消息反/序列化的讨论
- valueSerde
-
要使用的 value serde
默认值:请参阅上面关于消息反/序列化的讨论
- materializedAs
-
在使用传入 KTable 类型时要物化(materialize)的状态存储
默认值:
none。 - useNativeDecoding
-
启用/禁用原生解码的标志
默认值:
true。 - dlqName
-
DLQ topic 名称。
默认值:请参阅上面关于错误处理和 DLQ 的讨论。
- startOffset
-
如果没有已提交的 offset 可供消费,则从该 offset 开始消费。这主要在消费者首次消费 topic 时使用。Kafka Streams 使用
earliest作为默认策略,binder 也使用相同的默认值。可以使用此属性将其覆盖为latest。默认值:
earliest。
注意:在消费者端使用 resetOffsets 对 Kafka Streams binder 没有影响。与基于消息通道的 binder 不同,Kafka Streams binder 不会按需定位到开始或结束。
- deserializationExceptionHandler
-
反序列化错误处理程序类型。此处理程序应用于每个消费者 binding,而不是应用于 binder 级别的属性。可能的值包括 -
logAndContinue,logAndFail或sendToDlq默认值:
logAndFail - timestampExtractorBeanName
-
要在消费者端使用的特定时间戳提取器 bean 名称。应用可以将
TimestampExtractor作为 Spring bean 提供,并将该 bean 的名称提供给消费者,以代替默认提取器。默认值:请参阅上面关于时间戳提取器的讨论。
- eventTypes
-
此 binding 支持的事件类型列表,用逗号分隔。
默认值:
none - eventTypeHeaderKey
-
通过此 binding 传入的每个记录上的事件类型 header key。
默认值:
event_type - consumedAs
-
处理器从中消费的 source 组件的自定义名称。
默认值:
none(由 Kafka Streams 生成)
2.19.4. 并发性的特别说明
在 Kafka Streams 中,您可以使用 num.stream.threads 属性控制处理器可以创建的线程数。您可以使用上面在 binder、functions、producer 或 consumer 级别描述的各种 configuration 选项来实现这一点。您也可以使用核心 Spring Cloud Stream 为此目的提供的 concurrency 属性。使用此属性时,您需要在消费者端使用它。当函数或 StreamListener 中有多个输入 binding 时,请在第一个输入 binding 上设置此属性。例如,设置 spring.cloud.stream.bindings.process-in-0.consumer.concurrency 后,binder 将其转换为 num.stream.threads。如果您有多个处理器,其中一个处理器定义了 binding 级别的并发性,而其他处理器没有,则没有定义 binding 级别并发性的处理器将回退到通过 spring.cloud.stream.kafka.streams.binder.configuration.num.stream.threads 指定的 binder 范围属性。如果此 binder 配置不可用,则应用将使用 Kafka Streams 设置的默认值。
附录
附录 A: 构建
A.1. 基本编译和测试
要构建源代码,您需要安装 JDK 1.7。
构建使用 Maven wrapper,因此您无需安装特定版本的 Maven。要启用测试,您应该在构建之前运行 Kafka 服务器 0.9 或更高版本。有关运行服务器的更多信息,请参阅下文。
主构建命令是
$ ./mvnw clean install
您也可以添加 '-DskipTests' 来跳过运行测试(如果您愿意)。
您也可以自行安装 Maven(>=3.3.3),并在以下示例中使用 mvn 命令代替 ./mvnw。如果您这样做,并且您的本地 Maven 设置不包含 spring 预发布工件的仓库声明,您可能还需要添加 -P spring。 |
请注意,您可能需要通过设置 MAVEN_OPTS 环境变量来增加分配给 Maven 的内存量,例如设置为 -Xmx512m -XX:MaxPermSize=128m。我们已尝试在 .mvn 配置中涵盖这一点,因此如果您发现必须这样做才能使构建成功,请提交 issue,以便将这些设置添加到源代码管理中。 |
通常,需要中间件的项目会包含一个 docker-compose.yml 文件,因此可以考虑使用 Docker Compose 在 Docker 容器中运行中间件服务器。
A.2. 文档
有一个 "full" profile 将生成文档。
A.3. 使用代码
如果您没有 IDE 偏好,我们建议您在使用代码时使用 Spring Tools Suite 或 Eclipse。我们使用 m2eclipse Eclipse 插件来支持 Maven。其他 IDE 和工具也应该可以正常工作。
A.3.1. 使用 m2eclipse 导入到 Eclipse
我们建议在使用 Eclipse 时使用 m2eclipse Eclipse 插件。如果您尚未安装 m2eclipse,可以从“Eclipse Marketplace”获取。
遗憾的是,m2e 尚不支持 Maven 3.3,因此将项目导入 Eclipse 后,您还需要告诉 m2eclipse 使用项目中的 .settings.xml 文件。如果您不这样做,可能会看到与项目中 POM 相关的许多不同错误。打开 Eclipse 偏好设置,展开 Maven 偏好设置,然后选择 User Settings。在 User Settings 字段中,单击 Browse 并导航到您导入的 Spring Cloud 项目,选择该项目中的 .settings.xml 文件。点击 Apply 然后点击 OK 保存偏好设置更改。
或者,您可以将 .settings.xml 中的仓库设置复制到您自己的 ~/.m2/settings.xml 文件中。 |
A.3.2. 不使用 m2eclipse 导入到 Eclipse
如果您不想使用 m2eclipse,可以使用以下命令生成 Eclipse 项目元数据
$ ./mvnw eclipse:eclipse
生成的 Eclipse 项目可以通过从 file 菜单中选择 import existing projects 来导入。
[[contributing] == 贡献
Spring Cloud 以非限制性的 Apache 2.0 许可发布,并遵循非常标准的 Github 开发流程,使用 Github 跟踪器处理问题并将 pull requests 合并到 master 分支。如果您想贡献哪怕是微不足道的东西,请不要犹豫,但请遵循以下准则。
A.4. 签署贡献者许可协议
在我们接受非琐碎的补丁或 pull request 之前,我们需要您签署贡献者协议。签署贡献者协议并不授予任何人向主仓库提交代码的权利,但这确实意味着我们可以接受您的贡献,如果我们接受,您将获得作者署名。活跃的贡献者可能会被邀请加入核心团队,并获得合并 pull requests 的能力。
A.5. 代码约定和内务管理
以下所有项对于 pull request 来说都不是必不可少的,但它们都会有所帮助。它们也可以在原始 pull request 之后但在合并之前添加。
-
使用 Spring Framework 代码格式约定。如果您使用 Eclipse,可以使用 Spring Cloud Build 项目中的
eclipse-code-formatter.xml文件导入格式化程序设置。如果使用 IntelliJ,可以使用 Eclipse Code Formatter Plugin 导入相同的文件。 -
确保所有新的
.java文件都有一个简单的 Javadoc 类注释,至少包含一个标识您的@author标签,最好至少有一段描述该类的用途。 -
将 ASF 许可头注释添加到所有新的
.java文件(从项目中的现有文件复制)。 -
如果您对
.java文件进行了实质性修改(不仅仅是表面更改),请将自己添加为@author。 -
添加一些 Javadocs,如果更改了命名空间,还要添加一些 XSD 文档元素。
-
一些单元测试也会大有帮助——总得有人去做。
-
如果没有其他人使用您的分支,请将其基于当前的 master(或主项目中的其他目标分支)进行 rebase。
-
在编写提交消息时,请遵循这些约定,如果您正在修复现有问题,请在提交消息末尾添加
Fixes gh-XXXX(其中 XXXX 是问题编号)。